An easy observation is that if you have a chunking problem for which the majority of the chunks are multi-word tokens, then it is possible to get a model that achieves quite good accuracy, but abysmal f-score. Of course, real world taggers may not actually do this. What I wanted to know was the extent to which accuracy, f-score and ACE score are not correlated when used with a real world tagger.
Here's the experiment. I use TagChunk for all the experiments. I do experiments on both syntactic chunking (CoNLL data) and NER (also CoNLL data), both in English. In the experiments, I vary (A) the amount of training data used, (B) the size of the beam used by the model, (C) the number of iterations of training run. When (A) is varied, I run five sets of training data, each randomly selected.
The data set sizes I used are: 8, 16, 32, 64, 125, 250, 500, 1000, 2000, 4000 and 8000. (There are number of sentences, not words. For the NER data, I remove the "DOCSTART" sentences.) The beam sizes I use are 1, 5 and 10. The number of iterations is from 1 to 10.
For the chunking problem, I tracked Hamming accuracy and f-score (on test) in each of these settings. These are drawn below (click on the image for a bigger version):
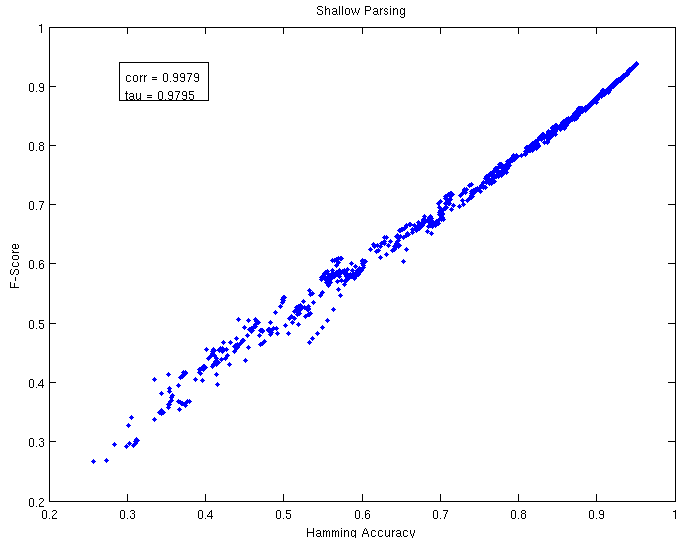
As we can see, the relationship is ridiculously strongly linear. Basically once we've gotten above an accuracy of 80%, it would be really really hard to improve accuracy and not improve F-score. The correlation coefficient for this data is 0.9979 and Kendall's tau is 0.9795, both indicating incredibly strong correlation (formal caveat: these samples are not independent).
For the NER task, I do the same experiments, but this time I keep track of accuracy, F-score and (a slightly simplified version of) the ACE metric. The results are below (again, click for a bigger version):

The left-most image is accuracy-versus-F, the middle is accuracy-versus-ACE and the right is F-versus-ACE. The ACE seems to be the outlier: it produces the least correlation. As before, with accuracy-to-F, we get a ridiculously high correlation coefficient (0.9959) and tau (0.9761). This drops somewhat when going to accuracy-to-ACE (corr=0.9596 and tau=0.9286) or to F-to-ACE (corr=0.9715 and tau=0.9253).
Nevertheless, the majority of the non-linearity occurs in the "very low accuracy" region. Here, that region is in the 0.8-0.9 range, not the 0.1-0.5 range as in chunking. This is because in chunking, almost every word is in a chunk, whereas in NER there are a ton of "out of chunk" words.
The take-away from these experiments is that it seems like, so long as you have a reasonably good model (i.e., once you're getting accuracies that are sufficiently high), it doesn't really matter what you optimize. If your model is terrible or if you don't have much data, then it does. It also seems to make a much bigger difference if the end metric is F or ACE. For F, it's pretty much always okay to just optimize accuracy. For ACE, it's not so much, particularly if you don't have sufficient data.