- A Discriminative Global Training Algorithm for Statistical MT (Tillmann and Zhang)
- Semi-Supervised Conditional Random Fields for Improved Sequence Segmentation and Labeling (Jiao, Wang, Lee, Greiner and Schuurmans)
- An Iterative Implicit Feedback Approach to Personalized Search (Lv, Sun, Zhang, Nie, Chen and Zhang)
- Training Conditional Random Fields with Multivariate Evaluation Measures (Suzuki, McDermott and Isozaki)
- Integrating Syntactic Priming into an Incremental Probabilistic Parser, with an Application to Psycholinguistic Modeling (Dubey, Keller and Sturt)
- Robust PCFG-Based Generation using Automatically Acquired LFG Approximations (Cahill and van Genabith)
- Exploiting Syntactic Patterns as Clues in Zero-Anaphora Resolution (Iida)
- An End-to-End Discriminative Approach to Machine Translation (Liang, Bouchard-Cote, Taskar and Klein)
31 May 2006
ACL papers up
Available here. Some that look especially interesting:
26 May 2006
Here's a Loss, There's a Loss
There are several different notions of "loss" that one encounters in machine learning literature. The definition I stick with is: the end criteria on which we will be evaluated. (The other notions often have to deal with how one approximates this loss for learning: for instance the standard loss for classification is 0/1, but this is approximated by hinge-loss or log-loss or...) For a large number of problems, there are quite a few "reasonable" losses. For chunking problems, there is 0/1 loss (did you get everything correct), Hamming loss (how many individual predictions did you get correct) and F-score (over chunks). For MT, there is WER, PER, HED, NIST, BLEU, etc. For summarization there are all the Rouges.
Some of these losses are easier to optimize than others (optimize from the learning perspective). The question that arises is: if I can optimize one, should I worry about any of the others? A positive answer would make our lives much easier, because we could ignore some of the complexities. A negative answer would mean that we, as machine learning people, would have to keep "chasing" the people inventing the loss functions.
It seems the answer is "yes and no." Or, more specifically, if the problem is sufficiently easy, then the answer is no. In all other cases, the answer is yes.
Arguments in favor of "no":
 On the x-axis is one loss function (say, hinge-loss) and on the y-axis is another (say, squared loss). Each dot corresponds to a different learning problem: those in the bottom left are easy, those in the top right are hard. What we commonly observe is that for very easy problems, it doesn't matter what loss you use (getting low error on one directly implies low error on another). However, as the problem gets harder, it makes a bigger and bigger difference which we use.
On the x-axis is one loss function (say, hinge-loss) and on the y-axis is another (say, squared loss). Each dot corresponds to a different learning problem: those in the bottom left are easy, those in the top right are hard. What we commonly observe is that for very easy problems, it doesn't matter what loss you use (getting low error on one directly implies low error on another). However, as the problem gets harder, it makes a bigger and bigger difference which we use.
A confounding factor which even further argues for "yes" is that in the binary classification example, the losses used are ones for which zero loss in one always implies zero loss for the other. This is very much not the case for the sorts of losses we encounter in NLP.
So, my personal belief is that if we can optimize the more complicated loss, we always should, unless the problem is so easy that it is unlikely to matter (eg, part of speech tagging). But for any sufficiently hard problem, it is likely to make a big difference. Though I would love to see some results that do the same experiment that Franz did in his MT paper, but also with human evaluations.
Some of these losses are easier to optimize than others (optimize from the learning perspective). The question that arises is: if I can optimize one, should I worry about any of the others? A positive answer would make our lives much easier, because we could ignore some of the complexities. A negative answer would mean that we, as machine learning people, would have to keep "chasing" the people inventing the loss functions.
It seems the answer is "yes and no." Or, more specifically, if the problem is sufficiently easy, then the answer is no. In all other cases, the answer is yes.
Arguments in favor of "no":
- All automatically evaluated loss functions are by definition approximations to the true loss. What does one more step of approximation hurt?
- The loss functions are rarely that different: I can often closely approximate loss B with a weighted version of loss A (and weighting is much easier than changing the loss entirely).
- Empirical evidence in sequence labeling/chunking problems and parsing show that optimizing 0/1 or Hamming or accuracy or F-score can all do very well.
- If not "yes" then reranking would not be such a popular technique (though it has other advantages in features).
- Empirical evidence in MT and summarization suggest that optimizing different different measures produces markedly different results (though how this translates into human evaluation is questionable).
- If effort is put in to finding an automatic criteria that closely correlates with human judgment, we should take advantage of it if we want to do well on human judgements.
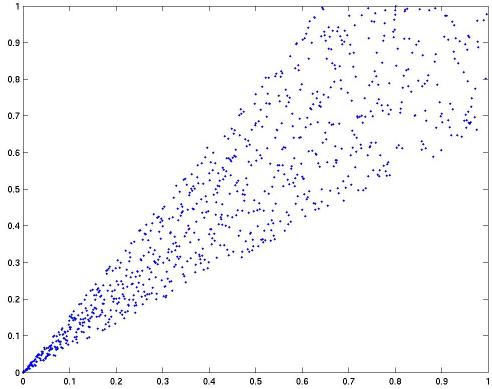 On the x-axis is one loss function (say, hinge-loss) and on the y-axis is another (say, squared loss). Each dot corresponds to a different learning problem: those in the bottom left are easy, those in the top right are hard. What we commonly observe is that for very easy problems, it doesn't matter what loss you use (getting low error on one directly implies low error on another). However, as the problem gets harder, it makes a bigger and bigger difference which we use.
On the x-axis is one loss function (say, hinge-loss) and on the y-axis is another (say, squared loss). Each dot corresponds to a different learning problem: those in the bottom left are easy, those in the top right are hard. What we commonly observe is that for very easy problems, it doesn't matter what loss you use (getting low error on one directly implies low error on another). However, as the problem gets harder, it makes a bigger and bigger difference which we use.A confounding factor which even further argues for "yes" is that in the binary classification example, the losses used are ones for which zero loss in one always implies zero loss for the other. This is very much not the case for the sorts of losses we encounter in NLP.
So, my personal belief is that if we can optimize the more complicated loss, we always should, unless the problem is so easy that it is unlikely to matter (eg, part of speech tagging). But for any sufficiently hard problem, it is likely to make a big difference. Though I would love to see some results that do the same experiment that Franz did in his MT paper, but also with human evaluations.
23 May 2006
Penn Discourse TreeBank
I visited Penn last November and while talking with Joshi, I found out about a recent annotation effort from Penn/LDC: the Penn Discourse Treebank. (There is also an upcoming tutorial at ACL about the effort). The PDTB is quite different from discourse resources I'm familiar with (eg., the RST treebank). The interesting aspect of the PDTB is that discourse connectives (either those that appear explicitly or those that are implicit) are treated as a sort of predicate between two arguments, much like one would expect for verbs.
As someone who is interested in problems that break the sentence boundary, I find much discourse-related resources and work interesting. One nice thing about the PDTB is that, since not every sentence is required to relate to another (relation only occurs when it is clear), human agreement is high and many unnatural decisions made in the RST treebank are avoided (eg., forcing things to be a tree when they shouldn't be). One not-so-nice thing about the PDTB is that not every sentence is required to relate to another. In a theory of discourse, I am looking for something that tells me why this blog post is a text and why a string of largely unrelated sentences are not. The PDTB-style annotation does not give us this. Because of this, it is hard for me to imagine many applications for which this is incredibly useful.
In case anyone more familiar with the PDTB group reads this blog, I'm curious if anyone has proposed baseline models and evaluation criteria for this problem. I have some ideas if there isn't anything out there, but I don't want to step on toes...
As someone who is interested in problems that break the sentence boundary, I find much discourse-related resources and work interesting. One nice thing about the PDTB is that, since not every sentence is required to relate to another (relation only occurs when it is clear), human agreement is high and many unnatural decisions made in the RST treebank are avoided (eg., forcing things to be a tree when they shouldn't be). One not-so-nice thing about the PDTB is that not every sentence is required to relate to another. In a theory of discourse, I am looking for something that tells me why this blog post is a text and why a string of largely unrelated sentences are not. The PDTB-style annotation does not give us this. Because of this, it is hard for me to imagine many applications for which this is incredibly useful.
In case anyone more familiar with the PDTB group reads this blog, I'm curious if anyone has proposed baseline models and evaluation criteria for this problem. I have some ideas if there isn't anything out there, but I don't want to step on toes...
21 May 2006
Getting Started In: Summarization
I'll kick off the "Getting Started In" series with summarization, since it is near and dear to my heart.
Warning: I should point out at the get-go that these posts are not intended to be comprehensive or present a representative sample of work in an area. These are blog posts, not survey papers, tutorials or anything of that sort. If I don't cite a paper, it's not because I don't think it's any good. It's also probably not a good idea to base a career move on what I say.
Summarization is the task of taking a long utterance (or a collection of long utterances) and producing a short utterance. The most common is when utterance=document, but there has also been work on speech summarization too. There are roughly three popular types of summarization: headline generation, sentence extraction and sentence compression (or document compression). In sentence extraction, a summary is created by selecting a bunch of sentences from the original document(s) and gluing them together. In headline generation, a very short summary (10 words or so) is created by selecting a bunch of words from the original document(s) and gluing them together. In sentence (document) compression a summary is created by dropping words and phrases from a sentence (document).
One of the big problems in summarization is that if you give two humans the same set of documents and ask them to write a summary, they will do wildly different things. This happens because (a) its unclear what information is important and (b) each human has different background knowledge. This is partially alleviated by moving to a task-specific setting, like the query-focused summarization model, which has grown increasingly popular in the past few years. In the query-focused setting, a document (or document collection) is provided along with a user query that serves to focus the summary on a particular topic. This doesn't fix problem (b), but goes a long way to fixing (a), and human agreement goes up dramatically. Another advantage to the query-focused setting is that, at least with news documents, the most important information is usually presented first (this is actually stipulated by many newspaper editor's guidelines). This means that producing a summary by just taking leading sentences often does incredibly well.
A related problem is that of evaluation. The best option is to do a human evaluation, preferably in some simulated real world setting. A reasonable alternative is to ask humans to write reference summaries and compare system output to these. The collection of Rouge metrics has been designed to automate this comparison (Rouge is essentially a collection of similarity metrics for matching human to system summaries). Overall, however, evaluation is a long-standing and not-well-solved problem in summarization.
Techniques for summarization vary by summary type (extraction, headline, compression).
The standard recipe for sentence extraction works as follows. A summary is created by first extracting the "best" sentence according to a scoring module. The second sentence is selected by finding the next-best sentence according to the scoring module, minus some redundancy penalty (we don't want to extract the same information over and over again). This process ends when the summary is sufficiently long. The scoring component assigns to each sentence in the original document collection a score that says how important it is (in query-focused summarization, for instance, the word overlap between the sentence and the query would be a start). The redundancy component typically computes the similarity between a sentence and the previously extracted sentences.
Headline generation and sentence compression have not yet reached a point of stability in the same way that sentence extraction has. A very popular and successful approach to headline generation is to train a hidden Markov model something like what you find in statistical machine translation (similar to IBM model 1, for those familiar with it). For sentence compression, one typically parses a sentence and then attempts to summarize it by dropping words and phrases (phrases = whole constituents).
Summarization has close ties to question answering and information retrieval; in fact, having some limited background in standard IR techniques (tf-idf, vector space model, etc.) are pretty much necessary in order to understand what goes on in summarization.
Here are some papers/tutorials/slides worth reading to get one started (I'd also recommend Inderjeet Mani's book, Automatic Summarization if you don't mind spending a little money):
Warning: I should point out at the get-go that these posts are not intended to be comprehensive or present a representative sample of work in an area. These are blog posts, not survey papers, tutorials or anything of that sort. If I don't cite a paper, it's not because I don't think it's any good. It's also probably not a good idea to base a career move on what I say.
Summarization is the task of taking a long utterance (or a collection of long utterances) and producing a short utterance. The most common is when utterance=document, but there has also been work on speech summarization too. There are roughly three popular types of summarization: headline generation, sentence extraction and sentence compression (or document compression). In sentence extraction, a summary is created by selecting a bunch of sentences from the original document(s) and gluing them together. In headline generation, a very short summary (10 words or so) is created by selecting a bunch of words from the original document(s) and gluing them together. In sentence (document) compression a summary is created by dropping words and phrases from a sentence (document).
One of the big problems in summarization is that if you give two humans the same set of documents and ask them to write a summary, they will do wildly different things. This happens because (a) its unclear what information is important and (b) each human has different background knowledge. This is partially alleviated by moving to a task-specific setting, like the query-focused summarization model, which has grown increasingly popular in the past few years. In the query-focused setting, a document (or document collection) is provided along with a user query that serves to focus the summary on a particular topic. This doesn't fix problem (b), but goes a long way to fixing (a), and human agreement goes up dramatically. Another advantage to the query-focused setting is that, at least with news documents, the most important information is usually presented first (this is actually stipulated by many newspaper editor's guidelines). This means that producing a summary by just taking leading sentences often does incredibly well.
A related problem is that of evaluation. The best option is to do a human evaluation, preferably in some simulated real world setting. A reasonable alternative is to ask humans to write reference summaries and compare system output to these. The collection of Rouge metrics has been designed to automate this comparison (Rouge is essentially a collection of similarity metrics for matching human to system summaries). Overall, however, evaluation is a long-standing and not-well-solved problem in summarization.
Techniques for summarization vary by summary type (extraction, headline, compression).
The standard recipe for sentence extraction works as follows. A summary is created by first extracting the "best" sentence according to a scoring module. The second sentence is selected by finding the next-best sentence according to the scoring module, minus some redundancy penalty (we don't want to extract the same information over and over again). This process ends when the summary is sufficiently long. The scoring component assigns to each sentence in the original document collection a score that says how important it is (in query-focused summarization, for instance, the word overlap between the sentence and the query would be a start). The redundancy component typically computes the similarity between a sentence and the previously extracted sentences.
Headline generation and sentence compression have not yet reached a point of stability in the same way that sentence extraction has. A very popular and successful approach to headline generation is to train a hidden Markov model something like what you find in statistical machine translation (similar to IBM model 1, for those familiar with it). For sentence compression, one typically parses a sentence and then attempts to summarize it by dropping words and phrases (phrases = whole constituents).
Summarization has close ties to question answering and information retrieval; in fact, having some limited background in standard IR techniques (tf-idf, vector space model, etc.) are pretty much necessary in order to understand what goes on in summarization.
Here are some papers/tutorials/slides worth reading to get one started (I'd also recommend Inderjeet Mani's book, Automatic Summarization if you don't mind spending a little money):
- Background IR material
- Sentence extraction
- Marcu's ACL tutorial
- Multi-Document Summarization By Sentence Extraction
- Automated Multi-document Summarization in NeATS
- A Trainable Document Summarizer
- Headline generation: Automatic Headline Generation for Newspaper Stories
- Sentence compression: Statistics-Based Summarization --- Step One: Sentence Compression
- Other:
- Discussion: What might be in a summary?
- Automatic evaluation: ROUGE: a Package for Automatic Evaluation of Summaries
- Recent fun stuff: Cut and paste based text summarization, Learning to Paraphrase: An Unsupervised Approach Using Multiple-Sequence Alignment and A Statistical Approach for Automatic Speech Summarization
16 May 2006
Structured Prediction versus Multitask Learning
For a formal comparison, I will briefly define both SP and MTL:
A structured prediction problem is a distribution D over pairs (x,y), with x in X and y in Y, together with a loss function l(y,y'). Typically Y is large, and elements y have complex interdependent structured, which can be interpreted in various ways. The goal is a function f : X -> Y that minimizes the expect loss: E_{x,y ~ D}[l(y,f(x))].
A multitask learning problem is a distribution D over tuples (x,y,y1,...,yK), with x in X and (for simplicity) y,y1,...,yK all in 2={0,1}. The goal is a function f : X -> 2 that minimizes the expected loss: E_{x,y,y1,...,yK ~ D}[1(y != f(x))]. Importantly the loss doesn't care about y1...yK. However, we typically assume that y1...yK are related to the x -> y mapping.
Without assumptions on the SP loss or output space Y, SP subsumes MTL. For instance, in sequence labeling, we can think of a multitask learning problem as a sequence labeling problem where we only care about the label of the first word. This reminds me of some results that suggest that it's really not any easier to predict the first word in a translation than to solve the entire translation problem. This means that we could try to solve an MTL problem by applying, say, a CRF.
One key difference that seems quite important is that results from MTL have suggested that it is easy to get an MTL model that performs better on the first task, but its hard to get a single MTL model that performs well on all tasks simultaneously. For instance, in neural networks, one might want to run 1000 training epochs to do well on task 1, but only 10 or as many as 10000 to do well on one of the other tasks. This implies that it's probably not a good idea to naively apply something like a CRF to an MTL problem. For this reason (and the nature of the loss functions), I feel that SP and MTL are complementary problems.
The application of MTL to time-series data has been reportedly very successful. Time-series data is nice because it naturally provides additional tasks: in addition to predicting the value at time t, also predict at times t+5, t+10 and t+20. During training we have access to these values, but we don't during testing, so we don't have the option of using them as features.
One especially cool thing about this observation is that it applies directly to search-based structured prediction! That is, when attempting to make a prediction about some search step, we can consider future search steps to be related tasks and apply MTL techniques. For instance, when trying to predict the first word in a translation, we use the second and third words as related tasks. I, personally, think this would be quite a cool research project.
So my tentative conclusions are: (1) SP can solve MTL, but this is probably not a good idea. (2) MTL can be applied to search-based SP and this probably is a good idea. (3) SP and MTL should not be considered the same problem: the primary difference is the loss function, which is all important to SP, but not so important to MTL. That said, SP algorithms probably do get a bit of gain from the "good internal representation" learned in an MTL setting, but by trying to learn this representation directly, we could probably do much better.
A structured prediction problem is a distribution D over pairs (x,y), with x in X and y in Y, together with a loss function l(y,y'). Typically Y is large, and elements y have complex interdependent structured, which can be interpreted in various ways. The goal is a function f : X -> Y that minimizes the expect loss: E_{x,y ~ D}[l(y,f(x))].
A multitask learning problem is a distribution D over tuples (x,y,y1,...,yK), with x in X and (for simplicity) y,y1,...,yK all in 2={0,1}. The goal is a function f : X -> 2 that minimizes the expected loss: E_{x,y,y1,...,yK ~ D}[1(y != f(x))]. Importantly the loss doesn't care about y1...yK. However, we typically assume that y1...yK are related to the x -> y mapping.
Without assumptions on the SP loss or output space Y, SP subsumes MTL. For instance, in sequence labeling, we can think of a multitask learning problem as a sequence labeling problem where we only care about the label of the first word. This reminds me of some results that suggest that it's really not any easier to predict the first word in a translation than to solve the entire translation problem. This means that we could try to solve an MTL problem by applying, say, a CRF.
One key difference that seems quite important is that results from MTL have suggested that it is easy to get an MTL model that performs better on the first task, but its hard to get a single MTL model that performs well on all tasks simultaneously. For instance, in neural networks, one might want to run 1000 training epochs to do well on task 1, but only 10 or as many as 10000 to do well on one of the other tasks. This implies that it's probably not a good idea to naively apply something like a CRF to an MTL problem. For this reason (and the nature of the loss functions), I feel that SP and MTL are complementary problems.
The application of MTL to time-series data has been reportedly very successful. Time-series data is nice because it naturally provides additional tasks: in addition to predicting the value at time t, also predict at times t+5, t+10 and t+20. During training we have access to these values, but we don't during testing, so we don't have the option of using them as features.
One especially cool thing about this observation is that it applies directly to search-based structured prediction! That is, when attempting to make a prediction about some search step, we can consider future search steps to be related tasks and apply MTL techniques. For instance, when trying to predict the first word in a translation, we use the second and third words as related tasks. I, personally, think this would be quite a cool research project.
So my tentative conclusions are: (1) SP can solve MTL, but this is probably not a good idea. (2) MTL can be applied to search-based SP and this probably is a good idea. (3) SP and MTL should not be considered the same problem: the primary difference is the loss function, which is all important to SP, but not so important to MTL. That said, SP algorithms probably do get a bit of gain from the "good internal representation" learned in an MTL setting, but by trying to learn this representation directly, we could probably do much better.
14 May 2006
NLP is an Engineering Discipline?
At my graduation ceremony this past week, Dean Yannis Yortsos gave a short speech, in which he quoted someone famous (I've already forgotten who it was) at the Engineering graduation segment, saying something akin to "Science is the study of what the world is; Engineering is making something the world has never seen before." This comment had a fairly significant effect on me. However, when thinking about it in the context of NLP, it seems that NLP is an Engineering discipline, not a scientific one, at least according to the above (implied) definition of the terms.
NLP lives somewhere within the realm of language, statistics, machine learning, and cognitive science (you can include signal processing if you want to account for speech). Let's suppose that NLP is a scientific discipline: then, what aspect of the world does it study? It cannot be language, otherwise we'd be linguists. It cannot be statistics or learning, lest we call ourselves mathematicians. Cognitive science is out or we'd be...well, cognitive scientists. In fact, at least as I've described it in my job talks, NLP is the field that deals with building systems to solve problems that have a language component. This seems to render NLP to fall exclusively within the realm of Engineering.
This observation seems to have several repurcussions. It means, among other things, that we should not attempt to seek theoretical results, unless we are wearing another hat (I often wear the hat of a machine learning person; other people play linguists occasionally). It also means that perhaps we shouldn't complain as much that so much of NLP is system building. It seems that almost by definition, NLP must be system building: we are out to create things that never existed before.
If one, like me, is interested in science---that is, the study of natural things in the world---it also means that we had better find some related topic (machine learning, cognitive science or linguistics) to study simultaneously.
NLP lives somewhere within the realm of language, statistics, machine learning, and cognitive science (you can include signal processing if you want to account for speech). Let's suppose that NLP is a scientific discipline: then, what aspect of the world does it study? It cannot be language, otherwise we'd be linguists. It cannot be statistics or learning, lest we call ourselves mathematicians. Cognitive science is out or we'd be...well, cognitive scientists. In fact, at least as I've described it in my job talks, NLP is the field that deals with building systems to solve problems that have a language component. This seems to render NLP to fall exclusively within the realm of Engineering.
This observation seems to have several repurcussions. It means, among other things, that we should not attempt to seek theoretical results, unless we are wearing another hat (I often wear the hat of a machine learning person; other people play linguists occasionally). It also means that perhaps we shouldn't complain as much that so much of NLP is system building. It seems that almost by definition, NLP must be system building: we are out to create things that never existed before.
If one, like me, is interested in science---that is, the study of natural things in the world---it also means that we had better find some related topic (machine learning, cognitive science or linguistics) to study simultaneously.
11 May 2006
ICML Accepted Papers Up
See here. I'm excited to see:
- Bayesian Multi-Population Haplotype Inference (Xing, Sohn, Jordan + Teh)
- Constructing Informative Priors using Transfer Learning (Raina, Ng + Koller)
- Disciminative Unsupervised Learning of Structured Predictors (Xu, Wilkinson, Southey + Schuurmans)
- Maximum Margin Planning (Ratliff, Bagnell + Zinkevich)
- Pachinko Allocation (Li + McCallum)
- Semi-supervised Learning for Structured Output Variables (Brefeld + Scheffer)
- Topic Modeling: Beyond Bag-of-Words (Wallach)
08 May 2006
Making Humans Agree
The question of human agreement came up recently. As background, the common state of affairs in NLP when someone has decided to work on a new problem is to ask two (or more) humans to solve the problem and then find some way to measure the inter-annotator agreement. The idea is that if humans can't agree on a task, then it is not worth persuing a computational solution. Typically this is an iterative process. First some guidelines are written, then some annotation is done, then more guidelines are written, etc. The hope is that this process converges after a small number of iterations. LDC has made a science out of this. At the very least, inter-annotator agreement serves as a useful upper bound on system performance (in theory a system could do better; in practice, it does not).
There are two stances one can take on the annotator agreement problem, which are diametrically opposed. I will attempt to argue for both.
The first stance is: If humans do not agree, the problem is not worth working on. (I originally wrote "solving" instead of "working on," but I think the weakened form is more appropriate.) The claim here is that if a problem is so ill-specified that two humans perform it so differently, then when a system does it, we will have no way of knowing if it is doing a good job. If it mimics one of the humans, that's probably okay. But if it does something else, we have no idea if human N+1 might also do this, so we don't know if its good or bad. Moreover, it will be very difficult to learn, since the target concept is annotator-specific. We want to learn general rules, not rules specific to annotators.
The second stance is: If humans do agree, the problem is not worth working on. This is the more controversial statement: I have never heard anyone else ever make it. The argument here is that any problem that humans agree on is either uninteresting or has gone through so many iterations of definitions and redefinitions as to render it uninteresting. In this case, the annotation guidelines are essentially an algorithm that the annotator is executing. Making a machine execute a similar algorithm is not interesting because what it is mimicing is not a natural process, but something created by the designers. Even without multiple iterations of guidelines, high human agreement implies that the task being solved is too artificial: personalization is simply too important of an issue when it comes to language problems.
My beliefs are somewhere in the middle. If humans cannot agree at all, perhaps the problem is too hard. But if they agree too much, or if the guidelines are overly strict, then the problem may have been sapped of its reality. One should also keep in mind that personalization issues can render agreement low; we see this all the time in summarization. I do not think this necessarily means that task should not be worked on: it just means if worked on, it should be a personalized task. Measuring agreement in such cases is something I know nothing about.
There are two stances one can take on the annotator agreement problem, which are diametrically opposed. I will attempt to argue for both.
The first stance is: If humans do not agree, the problem is not worth working on. (I originally wrote "solving" instead of "working on," but I think the weakened form is more appropriate.) The claim here is that if a problem is so ill-specified that two humans perform it so differently, then when a system does it, we will have no way of knowing if it is doing a good job. If it mimics one of the humans, that's probably okay. But if it does something else, we have no idea if human N+1 might also do this, so we don't know if its good or bad. Moreover, it will be very difficult to learn, since the target concept is annotator-specific. We want to learn general rules, not rules specific to annotators.
The second stance is: If humans do agree, the problem is not worth working on. This is the more controversial statement: I have never heard anyone else ever make it. The argument here is that any problem that humans agree on is either uninteresting or has gone through so many iterations of definitions and redefinitions as to render it uninteresting. In this case, the annotation guidelines are essentially an algorithm that the annotator is executing. Making a machine execute a similar algorithm is not interesting because what it is mimicing is not a natural process, but something created by the designers. Even without multiple iterations of guidelines, high human agreement implies that the task being solved is too artificial: personalization is simply too important of an issue when it comes to language problems.
My beliefs are somewhere in the middle. If humans cannot agree at all, perhaps the problem is too hard. But if they agree too much, or if the guidelines are overly strict, then the problem may have been sapped of its reality. One should also keep in mind that personalization issues can render agreement low; we see this all the time in summarization. I do not think this necessarily means that task should not be worked on: it just means if worked on, it should be a personalized task. Measuring agreement in such cases is something I know nothing about.
05 May 2006
Search-based Structured Prediction
I normally would not make a post such as this one (my blog is not my advertisementsphere), but given that it is unlikely this paper will appear in a conference in the near future (and conferences are just ads), I decided to include a link. John, Daniel and I have been working on an algorithm called Searn for solving structured prediction problems. I believe that it will be useful to NLP people, so I hope this post deserves the small space it takes up.
03 May 2006
Supervised Hidden Variable Models
Hidden variable models have been extremely successful in unsupervised NLP problems, such as the famous alignment models for machine translation. Recently, two parsing papers and a textual entailment paper have applied hidden variable techniques to supervised problems. I find this approach appealing because it allows one to learn hidden variable models that are (hopefully) optimal for the end goal. This contrasts with, or example, unsupervised word alignment, where it is unclear if the same alignment is good for two different tasks, for instance translation or projection.
The question that interests me is "what exactly are hidden variables in these models?" As a simple example, let's take the following problem: we have an English sentence and an Arabic sentence and we want to know if they're aligned. Dragos has a paper that shows that we can do a good job of making this determination if we do the following: construct an alignment (using, eg., GIZA++) and then compute features over the alignment (length of aligned subphrases, number of unaligned words, etc.). One can imagine similar models for textual entailment, paraphrase identification, etc.
I would ideally like to learn the alignments as part of training the classifier, treating them essentially as hidden variables in the supervised problem.
So what happens in such a model? We learn to produce alignments and then define features over the alignments. From an information theoretic perspective, we needn't bother with the alignments: we can just define features on the original sentence pair. Perhaps these features will be somewhat unnatural, but I don't think so. To build the alignments, we'll have features like "the word 'man' is aligned to the word 'XXX'" (where 'XXX' is Arabic for 'man'). Then on top of this we'd have features that count how many words are successfully aligned. It's somewhat unclear if this is much more than just including all word pair features for a pure classification technique.
The key difference appears to be in the fact that we impose a strong constraint on the alignments. For instance, that they are one-to-one or one-to-many or something similar. This significantly reduces the number of features that are fed into the classifier.
At the same time, the hidden variable models look a lot like introducing a hidden layer into a neural network! Consider a drastic simplification of the parallel sentence detection problem (which is, in the end, just a binary classification problem). Namely, consider the XOR problem. As we all know, we can't solve this with a linear classifier. But if we add a hidden variable to the mix, we can easily find a solution (eg., the hidden variable indicates left-versus-right and then conditional on this, we learn two separate classifiers, one pointing up and one pointing down). This is exactly what a two layer neural net (i.e., one hidden layer) would do!
From this perspective, it seems one can argue that hidden variable models are simply increasing the model complexity of the underlying learner. This comes at a cost: increased model complexity means we either need more data or stronger prior information. Hidden variable models --- more precisely, the constraints present in hidden variable models --- seem to provide this prior information.
The question that interests me is "what exactly are hidden variables in these models?" As a simple example, let's take the following problem: we have an English sentence and an Arabic sentence and we want to know if they're aligned. Dragos has a paper that shows that we can do a good job of making this determination if we do the following: construct an alignment (using, eg., GIZA++) and then compute features over the alignment (length of aligned subphrases, number of unaligned words, etc.). One can imagine similar models for textual entailment, paraphrase identification, etc.
I would ideally like to learn the alignments as part of training the classifier, treating them essentially as hidden variables in the supervised problem.
So what happens in such a model? We learn to produce alignments and then define features over the alignments. From an information theoretic perspective, we needn't bother with the alignments: we can just define features on the original sentence pair. Perhaps these features will be somewhat unnatural, but I don't think so. To build the alignments, we'll have features like "the word 'man' is aligned to the word 'XXX'" (where 'XXX' is Arabic for 'man'). Then on top of this we'd have features that count how many words are successfully aligned. It's somewhat unclear if this is much more than just including all word pair features for a pure classification technique.
The key difference appears to be in the fact that we impose a strong constraint on the alignments. For instance, that they are one-to-one or one-to-many or something similar. This significantly reduces the number of features that are fed into the classifier.
At the same time, the hidden variable models look a lot like introducing a hidden layer into a neural network! Consider a drastic simplification of the parallel sentence detection problem (which is, in the end, just a binary classification problem). Namely, consider the XOR problem. As we all know, we can't solve this with a linear classifier. But if we add a hidden variable to the mix, we can easily find a solution (eg., the hidden variable indicates left-versus-right and then conditional on this, we learn two separate classifiers, one pointing up and one pointing down). This is exactly what a two layer neural net (i.e., one hidden layer) would do!
From this perspective, it seems one can argue that hidden variable models are simply increasing the model complexity of the underlying learner. This comes at a cost: increased model complexity means we either need more data or stronger prior information. Hidden variable models --- more precisely, the constraints present in hidden variable models --- seem to provide this prior information.
01 May 2006
Getting Started in NLP
Since starting the blog, a few people have asked me how one can get started in NLP, while residing in a department lacking NLP researchers. This is a difficult question: I fell into NLP quite naturally when I was at CMU and made an easy transition to grad school at USC, both of which have awesome NLP groups. Lacking such internal support, one has to be much more ambitious to get to the point where one could do real research in the field. The obvious avenues for support are: reading books (which ones?) and papers (from where and by whom?), going to nearby conferences (which ones?) and experimentation (on what?). (New option: read and post to this blog!)
The four standard books in the field are Statistical NLP (Manning + Schutze), Speech and Language Processing (Jurafsky + Martin), Statistical Language Learning (Charniak) and Natural Language Understanding (Allen). The latter two are much older, though some people prefer Charniak to Manning + Schutze. I would probably pick up Manning + Schutze if I could only buy one. From this book, I think that skimming Chapters 1, 4, 6 and 13 should give a reasonable (but not uniformly sampled) representation of background knowledge everyone should know. Unfortunately, this misses many topics: information extraction, summarization, question answering, dialog systems, discourse, morphology, ontologies, pragmatics, semantics, sentiment analysis and textual entailment.
Finding good papers for beginners is hard. Without guidance, skimming titles and abstracts of papers published in ACL, NAACL, HLT or COLING since 2002 or 2003 should enable someone to find out what looks interesting to them. I know many advisors take this approach with new students. The ACL anthology is great for finding old papers. I'll probably post at a later date about what are the "must reads" for the areas I know best. Once you've found a few papers you like, I'd check out the respective author's web pages and see if they have any related work (best bet is probably to look at the advisor's page: often s/he will have multiple students working on similar topics). Also, advisor's often have course material and slides from tutorials: these are great places to get introductory-level material.
If you happen to get lucky (I never have) and one of the above conferences is located nearby, I'd just go. Presentations of papers (if they're good) are often better from the perspective of getting the high-level overview than the papers themselves, since papers have to be technically complete.
I'm perhaps overcommitting myself, given my promise to talk more about structured prediction, but over the next few weeks/months, I'll work on a "Getting Starting in X" series. X will likely range over the set { summarization, sequence labeling, information extraction, machine translation, language modeling }. Requests for other topics will be heard, keeping in mind I'm not an expert in many areas.
The four standard books in the field are Statistical NLP (Manning + Schutze), Speech and Language Processing (Jurafsky + Martin), Statistical Language Learning (Charniak) and Natural Language Understanding (Allen). The latter two are much older, though some people prefer Charniak to Manning + Schutze. I would probably pick up Manning + Schutze if I could only buy one. From this book, I think that skimming Chapters 1, 4, 6 and 13 should give a reasonable (but not uniformly sampled) representation of background knowledge everyone should know. Unfortunately, this misses many topics: information extraction, summarization, question answering, dialog systems, discourse, morphology, ontologies, pragmatics, semantics, sentiment analysis and textual entailment.
Finding good papers for beginners is hard. Without guidance, skimming titles and abstracts of papers published in ACL, NAACL, HLT or COLING since 2002 or 2003 should enable someone to find out what looks interesting to them. I know many advisors take this approach with new students. The ACL anthology is great for finding old papers. I'll probably post at a later date about what are the "must reads" for the areas I know best. Once you've found a few papers you like, I'd check out the respective author's web pages and see if they have any related work (best bet is probably to look at the advisor's page: often s/he will have multiple students working on similar topics). Also, advisor's often have course material and slides from tutorials: these are great places to get introductory-level material.
If you happen to get lucky (I never have) and one of the above conferences is located nearby, I'd just go. Presentations of papers (if they're good) are often better from the perspective of getting the high-level overview than the papers themselves, since papers have to be technically complete.
I'm perhaps overcommitting myself, given my promise to talk more about structured prediction, but over the next few weeks/months, I'll work on a "Getting Starting in X" series. X will likely range over the set { summarization, sequence labeling, information extraction, machine translation, language modeling }. Requests for other topics will be heard, keeping in mind I'm not an expert in many areas.