There are several different notions of "loss" that one encounters in machine learning literature. The definition I stick with is: the end criteria on which we will be evaluated. (The other notions often have to deal with how one approximates this loss for learning: for instance the standard loss for classification is 0/1, but this is approximated by hinge-loss or log-loss or...) For a large number of problems, there are quite a few "reasonable" losses. For chunking problems, there is 0/1 loss (did you get everything correct), Hamming loss (how many individual predictions did you get correct) and F-score (over chunks). For MT, there is WER, PER, HED, NIST, BLEU, etc. For summarization there are all the Rouges.
Some of these losses are easier to optimize than others (optimize from the learning perspective). The question that arises is: if I can optimize one, should I worry about any of the others? A positive answer would make our lives much easier, because we could ignore some of the complexities. A negative answer would mean that we, as machine learning people, would have to keep "chasing" the people inventing the loss functions.
It seems the answer is "yes and no." Or, more specifically, if the problem is sufficiently easy, then the answer is no. In all other cases, the answer is yes.
Arguments in favor of "no":
- All automatically evaluated loss functions are by definition approximations to the true loss. What does one more step of approximation hurt?
- The loss functions are rarely that different: I can often closely approximate loss B with a weighted version of loss A (and weighting is much easier than changing the loss entirely).
- Empirical evidence in sequence labeling/chunking problems and parsing show that optimizing 0/1 or Hamming or accuracy or F-score can all do very well.
Arguments in favor of "yes":
- If not "yes" then reranking would not be such a popular technique (though it has other advantages in features).
- Empirical evidence in MT and summarization suggest that optimizing different different measures produces markedly different results (though how this translates into human evaluation is questionable).
- If effort is put in to finding an automatic criteria that closely correlates with human judgment, we should take advantage of it if we want to do well on human judgements.
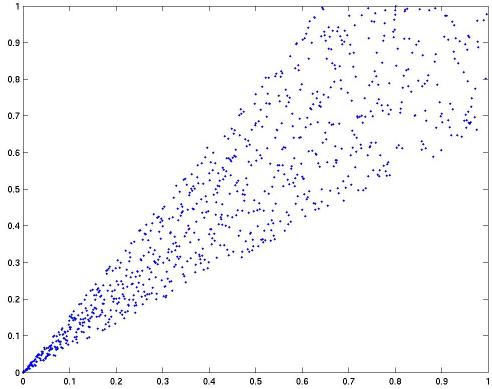
There is a fourth argument for "yes" which comes from the binary classification literature. If we solve hundreds of different classification problems, some of which are harder than others, we can compare directly how well one loss looks like another. The standard picture looks like that below:

On the x-axis is one loss function (say, hinge-loss) and on the y-axis is another (say, squared loss). Each dot corresponds to a different learning problem: those in the bottom left are easy, those in the top right are hard. What we commonly observe is that for very easy problems, it doesn't matter what loss you use (getting low error on one directly implies low error on another). However, as the problem gets harder, it makes a bigger and bigger difference which we use.
A confounding factor which even further argues for "yes" is that in the binary classification example, the losses used are ones for which zero loss in one
always implies zero loss for the other. This is very much not the case for the sorts of losses we encounter in NLP.
So, my personal belief is that if we can optimize the more complicated loss, we always should, unless the problem is so easy that it is unlikely to matter (eg, part of speech tagging). But for any sufficiently hard problem, it is likely to make a big difference. Though I would love to see some results that do the same experiment that Franz did in
his MT paper, but also with human evaluations.