Let (X,d) be a metric space (so X is a discrete set of points and d is a metric over the points of X). A clustering function F takes d as input and produces a clustering of the data. The three axioms Jon states that all clustering functions should satisfy are:
- Scale invariance: For all d, for all a>0, F(ad) = F(d). In other words, if I transform all my distances by scaling them uniformly, then the output of my clustering function should stay the same.
- Richness: The range of F is the set of all partitions. In other words, there isn't any bias that prohibits us from producing some particular partition.
- Consistency: Suppose F(d) gives some clustering, C. Now, modify d by shrinking distances within clusters of C and expanding distances between clusters in C. Call the new metric d'. Then F(d') = C.
If you think about these axioms a little bit, they kind of make sense. My problem is that if you think about them a lot of bit, you (or at least I) realize that they're broken. The biggest broken one is consistency, which becomes even more broken when combined with scale invariance.
What I'm going to do to convince you that consistency is broken is start with some data in which there is (what I consider) a natural clustering into two clusters. I'll then apply consistency a few times to get something that (I think) should yield a different clustering.
Let's start with some data. The colors are my opinion as to how the data should be clustered:
 I hope you agree with my color coding. Now, let's apply consistency. In particular, let's move some of the red points, only reducing inter-clustering distances. Formally, we find the closest pair of points and move things toward those.
I hope you agree with my color coding. Now, let's apply consistency. In particular, let's move some of the red points, only reducing inter-clustering distances. Formally, we find the closest pair of points and move things toward those. The arrows denote the directions these points will be moved. To make the situation more visually appealing, let's move things into lines:
The arrows denote the directions these points will be moved. To make the situation more visually appealing, let's move things into lines: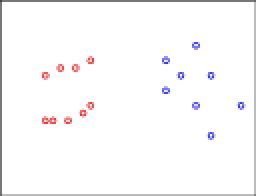 Okay, this is already looking funky. Let's make it even worse. Let's apply consistency again and start moving some blue points:
Okay, this is already looking funky. Let's make it even worse. Let's apply consistency again and start moving some blue points: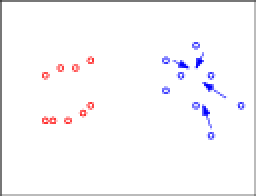 Again, let's organize these into a line:
Again, let's organize these into a line: And if I had given you this data to start with, my guess is the clustering you'd have come up with is more like:
And if I had given you this data to start with, my guess is the clustering you'd have come up with is more like: This is a violation of consistency.
This is a violation of consistency.So, what I'd like someone to do is to argue to my why consistency is actually a desirable property.
I can come up with lots of other examples. One reason why this invariance is bad is because it renders the notion of "reference sizes" irrelevant. This is of course a problem if you have prior knowledge (eg., one thing measured in millimeters, the other in kilometers). But even in the case where you don't know knowledge, what you can do is take the following. Take data generated by thousands of well separated Gaussians, so that the clearly right thing to do is have one cluster per Gaussian. Now, for each of these clusters except for one, shrink them down to single points. This is possible by consistency. Now, your data basically looks like thousands-1 of clusters with zero inter-cluster distances and then one cluster that's spread out. But now it seems that the reasonable thing is to put each data point that was in this old cluster into its own cluster, essentially because I feel like the other data shows you what clusters should look like. If you're not happy with this, apply scaling and push these points out super far from each other. (I don't think this example is as compelling as the one I drew in pictures, but I still think it's reasonable.
Now, in the UAI paper this year, they show that if you fix the number of clusters, these axioms are now consistent. (Perhaps this has to do with the fact that all of my "weird" examples change the number of clusters -- though frankly I don't think this is necessary... I probably could have arranged it so that the resulting green and blue clusters look like a single line that maybe should just be one cluster by itself.) But I still feel like consistency isn't even something we want.
(Thanks to the algorithms group at Utah for discussions related to some of these issues.)
UPDATE 20 JUNE 2009, 3:49PM EST
Here's some data to justify the "bad things happen even when the number of clusters stays the same" claim.
Start with this data:

Now, move some points toward the middle (note they have to spread to the side a bit so as not to decrease intra-cluster distances).

Yielding data like the following:

Now, I feel like two horizontal clusters are most natural here. But you may disagree. What if I add some more data (ie., this is data that would have been in the original data set too, where it clearly would have been a third cluster):

And if you still disagree, well then I guess that's fine. But what if there were hundreds of other clusters like that.
I guess the thing that bugs me is that I seem to like clusters that have similar structures. Even if some of these bars were rotated arbitrarily (or, preferably, in an axis-aligned manner), I would still feel like there's some information getting shared across the clusters.
The richness property also seems strange. In supervised learning we know that the learner has to have an inductive bias, otherwise it cannot generalize beyond what it has already seen. Shouldn't the case be the same in unsupervised learning? Shouldn't the clustering algorithm prefer some partitionings over the others?
ReplyDeleteYou're interpreting richness too strongly. All it says is that anything is possible. Our algorithm may be biased in any way it sees fit. (For example, most clustering algorithms are probably biased toward fewer clusters. This is probably good.)
ReplyDeleteOkay, I figured I should probably justify the "this is bad even when the number of clusters stays the same" thing. I've modified the post.
ReplyDeleteis part of the issue distinguishing between what a pattern (structure) and a cluster is? is there a deep distinction between the two?
ReplyDeleteit seems that the issue you have with the clustering axioms is that they allow transformations that lead to an alignment of data points in some pattern (like two lines), but in general, how should structure be defined and found over collections of data points? i think this has interesting connections to the perception of structure. matt dry, dan navarro and others have a paper in this year's cog sci comparing human clusterings to some simple machine learning algorithms (paper). it seems it would be interesting to compare how people cluster collections of points to machine learning algorithms. (there's already a wide body of work on how people cluster collections of point from a purely psychological point of view as well).
It's important to note three things:
ReplyDelete1) Some of the examples shown are not proper Consistent changes. The very first change you make in the counter-examples is actually not a valid Consistent change. This is because even though you are making points in the same clusters closer together, you are also making them closer to points in the other cluster. Specifically, by moving some of the bottom red points upwards, you are making them closer to some of the upper blue points. This is an illegal move with respect to Consistency.
2) Let us assume the changes were indeed Consistent ones, and you get the lines in the very last example. Once the Consistent change is finished, you seem to be asking yourself the question: "What is the most natural clustering here?". This is actually not the right question to be asking. Instead, you should be asking: "What is the most natural clustering here, GIVEN that the previous answer of the algorithm?". Consistency is not an axiom that helps you decide what is natural is natural, but rather it is there to ensure the clustering algorithm is at least self-affirming its own previous answers.
3) There is some confusion produced by thinking about this in 2d, or indeed any metric embedding. A more natural way to convince oneself is to think about an abstract distance matrix, and what consistent changes mean in that setting. When the number of clusters is fixed, Consistency is fairly non-contraversial. Encouraging evidence for this is that popular algorithms such as Single-Linkage (hierarchical) and the Min-Sum objective satisfy Consistency.
Slight typo in the last comment:
ReplyDelete"Consistency is not an axiom that helps you decide what is a natural clustering, but rather it is there to ensure the clustering algorithm is at least self-affirming its own previous answers."
One idea is to "guess" or learn the distribution each cluster has, and with that knowledge perform the clustering process respecting in your calculations the cluster distributions, which might alter
ReplyDeleteyour distance functions depending where you are located in space. Of course the distribution can be different in each dimension the data has.
Hello mate, I want to thank you for this nice blog. Would you mind telling me some secrets for a succesful blog ? Which could attract some visitors than it normally does. Please come visit my site Adoption Agencies Directory when you got time.
ReplyDeleteReza: "Consistency is not an axiom that helps you decide what is a natural clustering, but rather it is there to ensure the clustering algorithm is at least self-affirming its own previous answers."
ReplyDeleteHal's "first new look" intuition seems to me to be consistent with the math. It perhaps looks otherwise to you because he didn't specify that he was using the same "natural to him" clustering algorithm.
Hal: Are you sure it's allowable to argue against axiom 3 by positing new data sets?
Making axiom 3 more explicit should help. It's not this:
3. F(d) = C = F(d')
It's really this:
3'. G(d, X) = C = G(d', X)
with the appropriate conditions on d', and X is a data set. G is like F, but the data set it operates on is explicit. (I suppose F could have been a closure; in that case I've defunctionalized it.) It appears that you're arguing against this axiom:
3-hal. G(d, X) = C = G(d, X')
It's not clear to me that either axiom 3-hal or 3' is sufficient (along with 1 and 2) to prove the theorem, or that 3-hal and 3' are equivalent.
A second question, related to angle of attack. How general is this formulation of clustering? Can "G : Metric x Dataset -> Clustering" describe any clustering algorithm? Does it describe most popular clustering algorithms? Are there any known that can't be formulated like this?
Hello mate, I want to thank you for this nice blog. Would you mind telling me some secrets for a succesful blog ? Which could attract some visitors than it normally does. Please come visit my site FreeAdultEntertainment when you got time.
ReplyDeleteThis is just another reason why I like your website. I like your style of writing you tell your stories without out sending us to 5 other sites to complete the story. Please come visit my site Sioux Falls South Dakota Business Directory when you got time.
ReplyDeleteThis article was extremely interesting, especially since I was searching for thoughts on this subject last Thursday. Please come visit my site Chula Vista Business Directory when you got time.
ReplyDeleteIt is very interesting article and quite impressive and more informative and looking forward to read such article. Please come visit my site Modesto Yellow Page Business Directory when you got time
ReplyDeleteMe and my friend were arguing about an issue similar to this! Now I know that I was right. lol! Thanks for the information you post. Please come visit my site Roofing when you got time.
ReplyDeleteWhat a blog filled with vital and important information this is .. It must have taken a lot of hours for you to write these yourself. Hats off from me for your hard work. Please come visit my site
ReplyDeleteSignage when you got time.
I was thinking of looking up some of them newspaper websites, but am glad I came here instead. Although glad is not quite the right word… let me just say I needed this after the incessant chatter in the media, and am grateful to you for articulating something many of us are feeling - even from distant shores. Please come visit my site Phone Directory Of Newark City New Jersey NJ State when you got time.
ReplyDeleteYou may have not intended to do so, but I think you have managed to express the state of mind that a lot of people are in. The sense of wanting to help, but not knowing how or where, is something a lot of us are going through. Please come visit my site Local Business Directory Of Jersey City U.S.A. when you got time.
ReplyDeletethat your great job is clearly identifed. I was wondering if you offer any subscription to your RSS feeds as I would be very interested and can’t find any link to subscribe here. Please come visit my site Phone Directory Of Chula Vista City California CA State when you got time.
ReplyDeleteThis is just another reason why I like your website. I like your style of writing you tell your stories without out sending us to 5 other sites to complete the story. Please come visit my site Modesto Yellow Pages when you got time.
ReplyDeleteI really liked your blog! Please come visit my site Nashville Business Directory when you got time.
ReplyDeleteI enjoyed reading your work! GREAT post! I looked around for this… but I found you! Anyway, would you mind if I threw up a backlink from my site? Please come visit my site San Francisco Business Services And Classifieds when you got time.
ReplyDeleteI enjoyed reading your work! GREAT post! I looked around for this… but I found you! Anyway, would you mind if I threw up a backlink from my site? Please come visit my site California CA Phone Directory when you got time.
ReplyDeleteSo you expected tinkering to have rules and you are disappointed it has none?
ReplyDeleteOr do you believe in "meaning for free" à la Chris Anderson?
I see no reason why a randomly picked and massaged metric is supposed to highlight significant features.
Thank you for your good humor and for allowing yourself to be convinced that this was the right show for you to work on. Please come visit my site Bakersfield Yellow Page Business Directory when you got time.
ReplyDeleteThank you for your good humor and for allowing yourself to be convinced that this was the right show for you to work on. Please come visit my site Local Business Directory Of Bakersfield U.S.A. when you got time.
ReplyDeleteI wanted to thank you for this great read!! I definitely enjoying every little bit of it :) I have you bookmarked to check out new stuff you post. Please visit my Please visit my blog when you have time Please come visit my site City Guide Reno when you got time.
ReplyDeleteI wanted to thank you for this great read!! I definitely enjoying every little bit of it :) I have you bookmarked to check out new stuff you post. Please visit my Please visit my blog when you have time Please come visit my site Business Resources Comprehensive Listings when you got time.
ReplyDeleteMany institutions limit access to their online information. Making this information available will be an asset to all.
ReplyDeleteI do not buy Clustering Axioms either. I think you are so right about this.
ReplyDeletedenver mesothelioma lawyers