Says Piyush:
There was an interesting tutorial by Gunnar Martinsson on using randomization to speed-up matrix factorization (SVD, PCA etc) of really really large matrices (by "large", I mean something like 106 x 106). People typically use Krylov subspace methods (e.g., the Lanczos algo) but these require multiple passes over the data. It turns out that with the randomized approach, you can do it in a single pass or a small number of passes (so it can be useful in a streaming setting). The idea is quite simple. Let's assume you want the top K evals/evecs of a large matrix A. The randomized method draws K *random* vectors from a Gaussian and uses them in some way (details here) to get a "smaller version" of A on which doing SVD can be very cheap. Having got the evals/evecs of B, a simple transformation will give you the same for the original matrix A.The rest of this post are random thoughts that occurred to me at NIPS. Maybe some of them will get other people's wheels turning? This was originally an email I sent to my students, but I figured I might as well post it for the world. But forgive the lack of capitalization :):
The success of many matrix factorization methods (e.g., the Lanczos) also depends on how quickly the spectrum decays (eigenvalues) and they also suggest ways of dealing with cases where the spectrum doesn't quite decay that rapidly.
Some papers from the main conference that I found interesting:
Distribution Matching for Transduction (Alex Smola and 2 other guys): They use maximum mean discrepancy (MMD) to do predictions in a transduction setting (i.e., when you also have the test data at training time). The idea is to use the fact that we expect the output functions f(X) and f(X') to be the same or close to each other (X are training and X' are test inputs). So instead of using the standard regularized objective used in the inductive setting, they use the distribution discrepancy (measured by say D) of f(X) and f(X') as a regularizer. D actually decomposes over pairs of training and test examples so one can use a stochastic approximation of D (D_i for the i-th pair of training and test inputs) and do something like an SGD.
Semi-supervised Learning using Sparse Eigenfunction Bases (Sinha and Belkin from Ohio): This paper uses the cluster assumption of semi-supervised learning. They use unlabeled data to construct a set of basis functions and then use labeled data in the LASSO framework to select a sparse combination of basis functions to learn the final classifier.
Streaming k-means approximation (Nir Ailon et al.): This paper does an online optimization of the k-means objective function. The algo is based on the previously proposed kmeans++ algorithm.
The Wisdom of Crowds in the Recollection of Order Information. It's about aggregating rank information from various individuals to reconstruct the global ordering.
Dirichlet-Bernoulli Alignment: A Generative Model for Multi-Class Multi-Label Multi-Instance Corpora (by some folks at gatech): The problem setting is interesting here. Here the "multi-instance" is a bit of a misnomer. It means that each example in turn can consists of several sub-examples (which they call instances). E.g., a document consists of several paragraphs, or a webpage consists of text, images, videos.
Construction of Nonparametric Bayesian Models from Parametric Bayes Equations (Peter Orbanz): If you care about Bayesian nonparametrics. :) It basically builds on the Kolmogorov consistency theorem to formalize and sort of gives a recipe for the construction of nonparametric Bayesian models from their parametric counterparts. Seemed to be a good step in the right direction.
Indian Buffet Processes with Power-law Behavior (YWT and Dilan Gorur): This paper actually does the exact opposite of what I had thought of doing for IBP. The IBP (akin to the sense of the Dirichlet process) encourages the "rich-gets-richer" phenomena in the sense that a dish that has been already selected by a lot of customers is highly likely to be selected by future customers as well. This leads to the expected number of dishes (and thus the latent-features) to be something like O(alpha* log n). This paper tries to be even more aggressive and makes the relationship have a power-law behavior. What I wanted to do was a reverse behavior -- maybe more like a "socialist IBP" :) where the customers in IBP are sort of evenly distributed across the dishes.
persi diaconis' invited talk about reinforcing random walks... that is, you take a random walk, but every time you cross an edge, you increase the probability that you re-cross that edge (see coppersmith + diaconis, rolles + diaconis).... this relates to a post i had a while ago: nlpers.blogspot.com/2007/04/multinomial-on-graph.html ... i'm thinking that you could set up a reinforcing random walk on a graph to achieve this. the key problem is how to compute things -- basically want you want is to know for two nodes i,j in a graph and some n >= 0, whether there exists a walk from i to j that takes exactly n steps. seems like you could craft a clever data structure to answer this question, then set up a graph multinomial based on this, with reinforcement (the reinforcement basically looks like the additive counts you get from normal multinomials)... if you force n=1 and have a fully connected graph, you should recover a multinomial/dirichlet pair.
also from persi's talk, persi and some guy sergei (sergey?) have a paper on variable length markov chains that might be interesting to look at, perhaps related to frank wood's sequence memoizer paper from icml last year.
finally, also from persi's talk, steve mc_something from ohio has a paper on using common gamma distributions in different rows to set dependencies among markov chains... this is related to something i was thinking about a while ago where you want to set up transition matrices with stick-breaking processes, and to have a common, global, set of sticks that you draw from... looks like this steve mc_something guy has already done this (or something like it).
not sure what made me think of this, but related to a talk we had here a few weeks ago about unit tests in scheme, where they basically randomly sample programs to "hope" to find bugs... what about setting this up as an RL problem where your reward is high if you're able to find a bug with a "simple" program... something like 0 if you don't find a bug, or 1/
|P| if you find a bug with program P. (i think this came up when i was talking to percy -- liang, the other one -- about some semantics stuff he's been looking at.) afaik, no one in PL land has tried ANYTHING remotely like this... it's a little tricky because of the infinite but discrete state space (of programs), but something like an NN-backed Q-learning might do something reasonable :P.i also saw a very cool "survey of vision" talk by bill freeman... one of the big problems they talked about was that no one has a good p(image) prior model. the example given was that you usually have de-noising models like p(image)*p(noisy image|image) and you can weight p(image) by ^alpha... as alpha goes to zero, you should just get a copy of your noisy image... as alpha goes to infinity, you should end up getting a good image, maybe not the one you *want*, but an image nonetheless. this doesn't happen.
one way you can see that this doesn't happen is in the following task. take two images and overlay them. now try to separate the two. you *clearly* need a good prior p(image) to do this, since you've lost half your information.
i was thinking about what this would look like in language land. one option would be to take two sentences and randomly interleave their words, and try to separate them out. i actually think that we could solve this tasks pretty well. you could probably formulate it as a FST problem, backed by a big n-gram language model. alternatively, you could take two DOCUMENTS and randomly interleave their sentences, and try to separate them out. i think we would fail MISERABLY on this task, since it requires actually knowing what discourse structure looks like. a sentence n-gram model wouldn't work, i don't think. (although maybe it would? who knows.) anyway, i thought it was an interesting thought experiment. i'm trying to think if this is actually a real world problem... it reminds me a bit of a paper a year or so ago where they try to do something similar on IRC logs, where you try to track who is speaking when... you could also do something similar on movie transcripts.
hierarchical topic models with latent hierarchies drawn from the coalescent, kind of like hdp, but not quite. (yeah yeah i know i'm like a parrot with the coalescent, but it's pretty freaking awesome :P.)
That's it! Hope you all had a great holiday season, and enjoy your New Years (I know I'm going skiing. A lot. So there, Fernando! :)).

 I hope you agree with my color coding. Now, let's apply consistency. In particular, let's move some of the red points, only reducing inter-clustering distances. Formally, we find the closest pair of points and move things toward those.
I hope you agree with my color coding. Now, let's apply consistency. In particular, let's move some of the red points, only reducing inter-clustering distances. Formally, we find the closest pair of points and move things toward those. The arrows denote the directions these points will be moved. To make the situation more visually appealing, let's move things into lines:
The arrows denote the directions these points will be moved. To make the situation more visually appealing, let's move things into lines: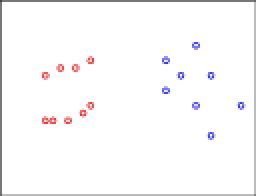 Okay, this is already looking funky. Let's make it even worse. Let's apply consistency again and start moving some blue points:
Okay, this is already looking funky. Let's make it even worse. Let's apply consistency again and start moving some blue points: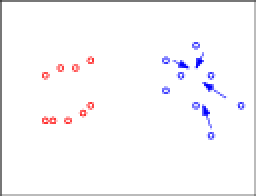 Again, let's organize these into a line:
Again, let's organize these into a line: And if I had given you this data to start with, my guess is the clustering you'd have come up with is more like:
And if I had given you this data to start with, my guess is the clustering you'd have come up with is more like: This is a violation of consistency.
This is a violation of consistency.


