I feel a bit odd doing my "what I liked at NAACL 2013" as one of the program chairs, but not odd enough to skip what seems to be the most popular type of post :). First, though, since Katrin Kirchhoff (my co-chair) and I never got a chance to formally thank Lucy Vanderwende (the general chair) and give her flowers (or wine or...) let me take this opportunity to say that Lucy was an amazing general chair and that working with her made even the least pleasant parts of PCing fun. So: thanks Lucy -- I can't imagine having someone better to have worked with! And all of the rest of you: if you see Lucy and if you enjoyed NAACL, please thank her!
I also wanted to really thank Matt Post for doing the NAACL app -- lots of people really liked it and I hope we do it in the future. I'm at ICML now and constantly wishing there were an ICML app :).
Okay, with that preface, let's get down to what you came for. Below is the list of my (complete) list of favorite papers from NAACL 2013 (also indexed on Braque) in no particular order:
- Relation Extraction with Matrix Factorization and Universal Schemas (N13-1008 by Sebastian Riedel; Limin Yao; Andrew McCallum; Benjamin M. Marlin)
Very cool paper. The idea is to try to jointly infer relations (think OpenIE-style) across text and databases, by writing everything down in a matrix and doing matrix completion. In particular, make the rows of this matrix equal to pairs of entities (Hal,UMD and UMD,DC-area) and the columns relations like "is-professor-at" and "is-located-in." These entity pairs and relations come both from free text and databases like FreeBase. Fill in the known entities and then think of it as a recommender system. They get great results with a remarkably straightforward approach. Reminds me a lot of my colleague Lise Getoor's work on multi-relational learning using tensor decompositions. - Combining multiple information types in Bayesian word segmentation (N13-1012 by Gabriel Doyle; Roger Levy)
I guess this qualifies as an "obvious in retrospect" idea -- and please recognize that I see that as a very positive quality! The basic idea is that stress patterns (eg trochees versus iambs) are very useful for kids (who apparently can recognize such things at 4 days old!) and are also very useful for word segmentation algorithms. - Learning a Part-of-Speech Tagger from Two Hours of Annotation (N13-1014 by Dan Garrette; Jason Baldridge)
Probably my overall favorite paper of the conference, and the title says everything. Also probably one of the best presentations I saw at the conference -- I can't even begin to guess how long Dan spent on his slides! I loved the question from Salim in the Q/A session, too: "Why did you stop at two hours?" (They have an ACL paper coming up, apparently, that answers this.) You should just read this paper.
- Automatic Generation of English Respellings (N13-1072 by Bradley Hauer; Grzegorz Kondrak)
This paper was the recipient of the best student paper award and, I thought, really great. It's basically about how English (in particular) has funny orthography and some times it's useful to map spellings to their pro-nun-see-ey-shuns, which most people find more useful than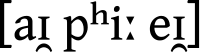 . It's a bit more of a bunch of stuff glued together than I usually go for in papers, but the ideas are solid and it seems to work pretty well -- and I'd never even thought this would be something interesting to look at, but it makes complete sense. Best part of presentation was when Greg tripped up pronouncing some example words :).
. It's a bit more of a bunch of stuff glued together than I usually go for in papers, but the ideas are solid and it seems to work pretty well -- and I'd never even thought this would be something interesting to look at, but it makes complete sense. Best part of presentation was when Greg tripped up pronouncing some example words :).
- Linguistic Regularities in Continuous Space Word Representations (N13-1090 by Tomas Mikolov; Wen-tau Yih; Geoffrey Zweig)
This is a paper that makes my list because it made me think. The basic idea is that if you do some representation learning thingamajig and then do vector space algebra like repr("King") - repr("man") + repr("woman") you end up with something that's similar to repr("Queen"). It's a really interesting observation, but I'm at a loss for why we would actually expect something like this to happen! - PPDB: The Paraphrase Database (N13-1092 by Juri Ganitkevitch; Benjamin Van Durme; Chris Callison-Burch)
This is a paper about a dataset release that I think I'll find useful and I bet other people will too. Go download it and play with it. I'd encourage the authors (are you listening, Juri!) to make a web demo (or web service) so that I don't need to go through the pain of getting it all set up to see if it might be useful for me. - Supervised Learning of Complete Morphological Paradigms (N13-1138 by Greg Durrett; John DeNero)
Basic idea: college morphological paradigms from Wiktionary and then train a supervised system to generalize from those to novel words. Works remarkably well and the model is well thought out. Plus I like papers that take morphology seriously: I wish we saw more stuff like this in NAACL.
- Improved Reordering for Phrase-Based Translation using Sparse Features (N13-1003 by Colin Cherry)

5 comments:
Hi,
since you like people/paper taking morphology seriously, may I point your audience to an ongoing shared task on parsing morphologically rich languages?
http://www.spmrl.org/spmrl2013-sharedtask.html
http://dokufarm.phil.hhu.de/spmrl2013/doku.php
9 languages (Arabic, Basque,French, German, Hebrew, Hungarian, Korean, Polish, Swedish) , constituency and dependency (and for some languages LCFRS style) and raw text parsing for French, Hebrew and Arabic.
Damn, I feel ashamed squatting your blog feed like that, feel free to remove it :)
Best,
Djamé
One thought about that Mikolov, Yih, and Zweig paper on representation algebra:
Imagine for a moment that our representations are just context vectors as used distributional similarity: counts or probabilities or weights of how often each other word occurred in a neighborhood of the given word. The vector repr("woman") - repr("man") would then be the differences in how often different words occur in the context of "woman" and "man". I looked at this in gigaword, and some of the biggest differences are "he", "she", "his", and "her". So now repr("king") + (repr("woman") - repr("man")) would be like taking all the contexts of "king", then replacing occurrences of "he" with occurrences of "she". Then it seems intuitively clear to me why repr("queen") should be the nearest neighbor.
Low dimensional projections should approximately preserve this property, I would think.
I think you and Daniel agree in regards to two papers you both liked, although Daniel lays down a bit of a gauntlet for unsupervised learning. :)
http://www.sdl.com/community/blog/details/35079/natural-language-processing-nlp-trends
Continuing Chris' line of thought, distributional similarity is often due to semantic similarity, there is nothing deeply surprising about finding "pants" and "jeans" in largely the same contexts. In an upcoming paper (ACL CVS Workshop, see http://kornai.com/Drafts/vectorsem.pdf) we tested the effect on antonyms. Remarkably, an embedding obtained from a dictionary (so that words are similar because their definitions are similar, not because their contexts are) show the same effect.
Andras
"semantic similarity is distributional similarity"
Fixed that for you.
/channelingFirth
Post a Comment