This will probably be a bit briefer than my corresponding NAACL post because even by day two of ICML, I was a bit burnt out; I was also constantly swapping in other tasks (grants, etc.). Note that John has already posted his list of papers.
- #317: Multi-View Clustering via Canonical Correlation Analysis (Chaudhuri, Kakade, Livescu, Sridharan). This paper shows a new application of CCA to clustering across multiple views. They use some wikipedia data in experiments and actually prove something about the fact that (under certain multi-view-like assumptions), CCA does the "right thing."
- #295: Learning Nonlinear Dynamic Models (Langford, Salakhutdinov,, Zhang). The cool idea here is to cut a deterministic classifier in half and use its internal state as a sort of sufficient statistic. Think about what happens if you represent your classifier as a circuit (DAG); then anywhere you cut along the circuit gives you a sufficient representation to predict. To avoid making circuits, they use neural nets, which have an obvious "place to cut" -- namely, the internal nodes.
- #364: Online Dictionary Learning for Sparse Coding (Mairal, Bach, Ponce, Sapiro). A new approach to sparse coding; the big take-away is that it's online and fast.
- 394: MedLDA: Maximum Margin Supervised Topic Models for Regression and Classification (Zhu, Ahmed, Xing). This is a very cute idea for combining objectives across topic models (namely, the variational objective) and classification (the SVM objective) to learn topics that are good for performing a classification task.
- #393: Learning from Measurements in Exponential Families (Liang, Jordan, Klein). Suppose instead of seeing (x,y) pairs, you just see some statistics on (x,y) pairs -- well, you can still learn. (In a sense, this formalizes some work out of the UMass group; see also the Bellare, Druck and McCallum paper at UAI this year.)
- #119: Curriculum Learning (Bengio, Louradour, Collobert, Weston). The idea is to present examples in a well thought-out order rather than randomly. It's a cool idea; I've tried it in the context of unsupervised parsing (the unsearn paper at ICML) and it never helped and often hurt (sadly). I curriculum-ified by sentence length, though, which is maybe not a good model, especially when working with WSJ10 -- maybe using vocabulary would help.
- #319: A Stochastic Memoizer for Sequence Data (Wood, Archambeau, Gasthaus, James, Whye Teh). If you do anything with Markov models, you should read this paper. The take away is: how can I learn a Markov model with (potentially) infinite memory in a linear amount of time and space, and with good "backoff" properties. Plus, there's some cool new technology in there.
- A Uniqueness Theorem for Clustering Reza Bosagh Zadeh, Shai Ben-David. I already talked about this issue a bit, but the idea here is that if you fix k, then the clustering axioms become satisfiable, and are satisfied by two well known algorithms. Fixing k is a bit unsatisfactory, but I think this is a good step in the right direction.
- Convex Coding David Bradley, J. Andrew Bagnell. The idea is to make coding convex by making it infinite! And then do something like boosting.
- On Smoothing and Inference for Topic Models Arthur Asuncion, Max Welling, Padhraic Smyth, Yee Whye Teh. If you do topic models, read this paper: basically, none of the different inference algorithms do any better than the others (perplexity-wise) if you estimate hyperparameters well. Come are, of course, faster though.
- Correlated Non-Parametric Latent Feature Models Finale Doshi-Velez, Zoubin Ghahramani. This is an indian-buffet-process-like model that allows factors to be correlated. It's somewhat in line with our own paper from NIPS last year. There's still something a bit unsatisfactory in both our approach and their approach that we can't do this "directly."
- Domain Adaptation: Learning Bounds and Algorithms. Yishay Mansour, Mehryar Mohri and Afshin Rostamizadeh. Very good work on some learning theory for domain adaptation based on the idea of stability.
 I hope you agree with my color coding. Now, let's apply consistency. In particular, let's move some of the red points, only reducing inter-clustering distances. Formally, we find the closest pair of points and move things toward those.
I hope you agree with my color coding. Now, let's apply consistency. In particular, let's move some of the red points, only reducing inter-clustering distances. Formally, we find the closest pair of points and move things toward those. The arrows denote the directions these points will be moved. To make the situation more visually appealing, let's move things into lines:
The arrows denote the directions these points will be moved. To make the situation more visually appealing, let's move things into lines: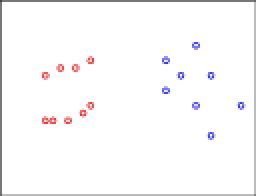 Okay, this is already looking funky. Let's make it even worse. Let's apply consistency again and start moving some blue points:
Okay, this is already looking funky. Let's make it even worse. Let's apply consistency again and start moving some blue points: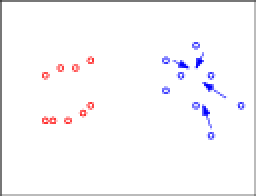 Again, let's organize these into a line:
Again, let's organize these into a line: And if I had given you this data to start with, my guess is the clustering you'd have come up with is more like:
And if I had given you this data to start with, my guess is the clustering you'd have come up with is more like: This is a violation of consistency.
This is a violation of consistency.




