There are tons of "how to apply for academic jobs" write-ups out there; this is not one of them. It's been four years (egads!) since I began my job search and there are lots of things I think I did well and lots of things I wish I had done differently.
When I entered grad school, I was fairly sure that I eventually wanted a university job. During high school, my career goal was to be a high school math teacher. Then I went to college and realized that, no, I wanted to teach math to undergraduates. Then I was an advanced undergraduate and realized that I wanted to teach grads and do research. Teaching was always very important to me, though of course I fell in love with research later. It was unfortunate that it took so long for me to actually get involved in research, but my excuse was that I wasn't in CS, where REU-style positions are plentiful and relatively easy to come by (system development, anyone?).
However, the more time I spend in grad school, including an internship at MSR with Eric Brill (but during which I befriended many in the NLP group at MSR, a group that I still love), I realized that industry labs were a totally great place to go, too.
I ended up applying to basically everything under the sun, provided they had a non-zero number of faculty in either NLP or ML. I talked (mostly off the record) with a few people about post-doc positions (I heard later than simultaneously exploring post-docs and academic positions is not a good idea: hiring committees don't like to "reconsider" people; I don't know how true this is, but I heard it too late myself to make any decisions based on it), applied for some (okay, many) tenure-track positions, some research-track positions (okay, few) and to the big three industry labs. I wrote three cover letters, one more tailored to NLP, one more to ML and one more combined, three research statements (ditto) and one teaching statement. In retrospect, they were pretty reasonable, I think, though not fantastic. I don't think I did enough to make my future research plans not sound like "more of the same."
I suppose my biggest piece of advice for applying is (to the extent possible) find someone you know and trust at the institution and try to figure out exactly what they're looking for. Obviously you can't change who you are and the work you've done, but you definitely can sell it in slightly different ways. This is why I essentially had three application packages -- the material was the same, the focus was different. But, importantly, they were all true. The more this person trusts you, the more of the inside scoop they can give you. For instance, we had a robotics/ML position open (which, sadly, we had to close due to budget issues), but in talking to several ML people, they felt that they weren't sufficiently "robotics" enough; I think I was able to dissuade them of this opinion and we ended up getting a lot of excellent applicants before we shut down the slot.
Related, it's hard to sell yourself across two fields. At the time I graduated, I saw myself as basically straddling NLP and ML. This can be a hard sell to make. I feel in retrospect that you're often better off picking something and really selling that aspect. From the other side of the curtain, what often happens is that you need an advocate (or two) in the department to which you're applying. If you sell yourself as an X person, you can get faculty in X behind you; if you sell yourself as a Y person, you can get faculty in Y behind you. However, if you sell yourself as a mix, the X faculty might prefer a pure X and the Y faculty might prefer a pure Y. Of course, this isn't always true: Maryland is basically looking for a combined NLP/ML person this year to compliment their existing strengths. Of course, this doesn't always hold: this is something that you should try to find out from friends at the places to which you're applying.
For the application process itself, my experience here and what I've heard from most (but not all) universities is that interview decisions (who to call in) get made by a topic-specific hiring committee. This means that to get in the door, you have to appeal to the hiring committee, which is typically people in your area, if it's an area-specific call for applications. Typically your application will go to an admin, first, who will filter based on your cover letter to put you in the right basket (if there are multiple open slots) or the waste basket (for instance, if you don't have a PhD). It then goes to the hiring committee. Again, if you have a friend in the department, it's not a bad idea to let them know by email that you've applied after everything has been submitted (including letters) to make sure that you don't end up in the waste bin.
Once your application gets to the hiring committee, the hope is that they've already heard of you. But if they haven't, hopefully they've heard of at least one of your letter writers. When we get applications, I typically first sort by whether I've heard of the applicant, then by the number of letter writers they have that I've heard of, then loosely by the reputation of their university. And I make my way down the list, not always all the way to the bottom. (Okay, I've only done this once, and I think I got about 90% of the way through.)
In my experience, what we've looked for in applications is (a) a good research statement, including where you're going so as to distinguish yourself from your advisor, (b) a not-bad teaching statement (it's hard to get a job at a research university on a great teaching statement, but it's easy to lose an offer on a bad one... my feeling here is just to be concrete and not to pad it with BS -- if you don't have much to say, don't say much), (c) great letters, and (d) an impressive CV. You should expect that the hiring committee will read some of your papers before interviewing you. This means that if you have dozens, you should highlight somewhere (probably the research statement) what are they best ones that they should read. Otherwise they'll choose essentially randomly, and (depending on your publishing style) this could hurt. As always, put your best foot forward and make it easy for the hiring committee to find out what's so great about you.
Anyway, that's basically it. There's lots more at interview stage, but these are my feelings for application stage. I'd be interested to hear if my characterization of the hiring process is vastly different than at other universities; plus, if there are other openings that might be relevant to NLP/ML folks, I'm sure people would be very pleased to seem them in the comments section.
Good luck, all your graduating folks!
25 September 2009
Some notes on job search
09 September 2009
Where did you Apply to Grad School?
Ellen and I are interested (for obvious reasons) in how people choose what schools to apply to for grad school. Note that this is not the question of how you chose where to go. This is about what made the list of where you actually applied. We'd really appreciate if you'd fill out our 10-15 minute survey and pass it along to your friends (and enemies). If you're willing, please go here.
07 September 2009
ACL and EMNLP retrospective, many days late
Well, ACL and EMNLP are long gone. And sadly I missed one day of each due either to travel or illness, so most of my comments are limited to Mon/Tue/Fri. C'est la vie. At any rate, here are the papers I saw or read that I really liked.
P09-1010 [bib]: S.R.K. Branavan; Harr Chen; Luke Zettlemoyer; Regina Barzilay
Reinforcement Learning for Mapping Instructions to Actions
andP09-1011 [bib]: Percy Liang; Michael Jordan; Dan Klein
Learning Semantic Correspondences with Less Supervision
these papers both address what might roughly be called the grounding problem, or at least trying to learn something about semantics by looking at data. I really really like this direction of research, and both of these papers were really interesting. Since I really liked both, and since I think the directions are great, I'll take this opportunity to say what I felt was a bit lacking in each. In the Branavan paper, the particular choice of reward was both clever and a bit of a kludge. I can easily imagine that it wouldn't generalize to other domains: thank goodness those Microsoft UI designers happened to call the Start Button something like UI_STARTBUTTON. In the Liang paper, I worry that it relies too heavily on things like lexical match and other very domain specific properties. They also should have cited Fleischman and Roy, which Branavan et al did, but which many people in this area seem to miss out on -- in fact, I feel like the Liang paper is in many ways a cleaner and more sophisticated version of the Fleischman paper.P09-1054 [bib]: Yoshimasa Tsuruoka; Jun’ichi Tsujii; Sophia Ananiadou
Stochastic Gradient Descent Training for L1-regularized Log-linear Models with Cumulative Penalty
This paper is kind of an extension of the truncated gradient approach to learning l1-regularized models that John, Lihong and Tong had last year at NIPS. The paper did a great job at motivated why L1 penalties is hard. The first observation is that L1 regularizes optimized by gradient steps like to "step over zero." This is essentially the observation in truncated gradient and frankly kind of an obvious one (I always thought this is how everyone optimized these models, though of course John, Lihong and Tong actually proved something about it). The second observation, which goes into this current paper, is that you often end up with a lot of non-zeros simply because you haven't run enough gradient steps since the last increase. They have a clever way to accumulating these penalties lazily and applying them at the end. It seems to do very well, is easy to implement, etc. But they can't (or haven't) proved anything about it.P09-1057 [bib]: Sujith Ravi; Kevin Knight
Minimized Models for Unsupervised Part-of-Speech Tagging
I didn't actually see this paper (I think I was chairing a session at the time), but I know about it from talking to Sujith. Anyone who considers themselves a Bayesian in the sense of "let me put a prior on that and it will solve all your ills" should read this paper. Basically they show that sparse priors don't give you things that are sparse enough, and that by doing some ILP stuff to minimize dictionary size, you can get tiny POS tagger models that do very well.- D09-1006: [bib]
Omar F. Zaidan Chris Callison-Burch
Feasibility of Human-in-the-loop Minimum Error Rate Training
Chris told me about this stuff back in March when I visited JHU and I have to say I was totally intrigued. Adam already discussed this paper in an earlier post, so I won't go into more details, but it's definitely a fun paper. - D09-1011: [bib]
Markus Dreyer Jason Eisner
Graphical Models over Multiple Strings
This paper is just fun from a technological perspective. The idea is to have graphical models, but where nodes are distributions over strings represented as finite state automata. You do message passing, where your messages are now automata and you get to do all your favorite operations (or at least all of Jason's favorite operations) like intersection, composition, etc. to compute beliefs. Very cool results. - D09-1024: [bib]
Ulf Hermjakob
Improved Word Alignment with Statistics and Linguistic Heuristics
Like the Haghighi coreference paper below, here we see how to do word alignment without fancy math! - D09-1120: [bib]
Aria Haghighi Dan Klein
Simple Coreference Resolution with Rich Syntactic and Semantic Features
How to do coreference without math! I didn't know you could still get papers accepted if they didn't have equations in them!
14 August 2009
Classifier performance: alternative metrics of success
I really enjoyed Mark Dredze's talk at EMNLP on multiclass confidence weighted algorithms, where they take their CW binary predictors and extend them in two (basically equivalent) ways to a multiclass/structured setting (warning: I haven't read the paper!). Mark did a great job presenting, as always, and dryly suggested that we should all throw away our perceptrons and our MIRAs and SVMs and just switch to CW permanently. It was a pretty compelling case.
Now, I'm going to pick on basically every "yet another classifier" paper I've read in the past ten years (read: ever). I'm not trying to point fingers, but just try to better understand why I, personally, haven't yet switched to using these things and continue to use either logistic regression or averaged perceptron for all of my classification needs (aside from the fact that I am rather fond of a particular software package for doing these things -- note, though, that it does support PA and maybe soon CW if I decide to spend 10 minutes implementing it!).
Here's the deal. Let's look at SVM versus logreg. Whether this is actually true or not, I have this gut feeling that logreg is much less sensitive to hyperparameter selection than are SVMs. This is not at all based on any science, and the experience that it's based on it somewhat unfair (comparing megam to libSVM, for instance, which use very different optimization methods, and libSVM doesn't do early stopping while megam does). However, I've heard from at least two other people that they have the same internal feelings. In other words, here's a caricature of how I believe logreg and SVM behave:
That is, if you really tune the regularizer (lambda) well, then SVMs will win out. But for the majority of the settings, they're either the same or logreg is a bit better.
As a result, what do I do? I use logreg with lambda=1. That's it. No tuning, no nothing.
(Note that, as I said before, I haven't ever run experiments to verify this. I think it would be a moderately interesting thing to try to see if it really holds up when all else -- eg., the optimization algorithm, early stopping, implementation, choice of regularizer (L1, L2, KL, etc.), and so on -- are held constant... maybe it's not true. But if it is, then it's an interesting theoretical question: hinge loss and log loss don't look that different, despite the fact that John seems to not like how log loss diverges: why should this be true?)
This is also why I use averaged perceptron: there aren't any hyperparameters to select. It just runs.
What I'd really like to see in future "yet another classifier" papers is an analysis of sensitivity to hyperparameter selection. You could provide graphs and stuff, but these get hard to read. I like numbers. I'd like a single number that I can look at. Here are two concrete proposals for what such a number could be (note: I'm assuming you're also going to provide performance numbers at the best possible selection of hyperparameters from development data or cross validation... I'm talking about something in addition):

- Performance at a default setting of the hyperparameter. For instance, SVM-light uses something like average inverse norm of the data vectors as the C parameter. Or you could just us 1, like I do for logreg. In particular, suppose you're testing your algorithm on 20 data sets from UCI. Pick a single regularization parameter (or parameter selection scheme, ala SVM-light) to use for all of them and report results using that value. If this is about the same as the "I carefully tuned" setting, I'm happy. If it's way worse, I'm not so happy.
- Performance within a range. Let's say that if I do careful hyperparameter selection then I get an accuracy of X. How large is the range of hyperparameters for which my accuracy is at least X*0.95? I.e., if I'm willing to suffer 5% multiplicative loss, how lazy can I be about hp selection? For this, you'll probably need to grid out your performance and then do empirical integration to approximate this. Of course, you'll need to choose a bounded range for your hp (usually zero will be a lower bound, but you'll have to pick an upper bound, too -- but this is fine: as a practitioner, if you don't give me an upper bound, I'm going to be somewhat unhappy).
(As an aside, Mark, if you're reading this, I can imagine the whole CW thing getting a bit confused if you're using feature hashing: have you tried this? Or has someone else?)
03 August 2009
ACS: Machine Translation Papers at EMNLP
[Guest Post by Adam Lopez... thanks, Adam! Hal's comment: you may remember that a while ago I proposed the idea of conference area chairs posting summaries of their areas; well, Adam is the first to take me up on this idea... I still think it's a good idea, so anyone else who wants to do so in the future, let me know!]
Conferences can be exhausting, and back-to-back conferences can be really exhausting, so I want to convince you to pace yourself and save some energy for EMNLP at the end of the week, because we have some really interesting MT papers. I'll focus mainly on oral presentations, because unlike poster sessions, the parallel format of the oral sessions entails a hard choice between mutually exclusive options, and part of my motivation is to help you make that choice. That being said, there are many interesting papers at the poster session, so do take a look at them!
MT is a busy research area, and we have a really diverse set of papers covering the whole spectrum of ideas: from blue sky research on novel models, formalisms, and algorithms, to the hard engineering problems of wringing higher accuracy and speed out of a mature, top-scoring NIST system. I occasionally feel that my colleagues on far reaches of either side of this spectrum are too dismissive of work on the other side; we need both if we're going to improve translation.
Outside the Box
Before giving you a guided tour through that spectrum, I want to highlight one paper that I found thought-provoking, but hard to classify. Zaidan & Callison-Burch question a basic assumption underlying most machine learning approaches to NLP: that we must optimize on an easily computable approximation to the true loss function. They ask: why not optimize for human judgement? They design a metric that uses judgements on small snippets of a target sentence (defined by a spanning nonterminal in a parse tree of the aligned source sentence) and figure how many judgements they would need to collect (using Amazon Mechanical Turk) to cover an iteration of MERT, exploiting the fact that these snippets reoccur repeatedly during optimization. How hard is this exactly? I would say, in terms of this scale of loss functions, that their metric is a 2. Yet, it turns out to be cheap and fast to compute. The paper doesn't report results of an actual optimization run, but it's in the works... hopefully you'll learn more at the conference.
Connecting Theory and Practice
A few papers combine deep theoretical insight with convincing empirical results. Hopkins & Langmead improve on cube pruning, a popular approximate search technique for structured models with non-local features (i.e. translation with an integrated language model). They move cube pruning from its ad hoc roots to a firm theoretical basis by constructing a reduction to A* search, connecting it to classical AI search literature. This informs the derivation of new heuristics for a syntax-based translation model, including an admissible heuristic to perform exact cube pruning. It's still globally approximate, but exact for the local prediction problem that cube pruning solves (i.e., what are the n-best state splits of an item, given the n-best input states from previous deductions?). Amazingly, this is only slightly slower than the inexact version and improves the accuracy of a strong baseline on a large-scale Arabic-English task.
Li & Eisner show how to compute a huge number of statistics efficiently over a combinatorially large number of hypotheses represented in a hypergraph. The statistics include expected hypothesis length, feature expectation, entropy, cross-entropy, KL divergence, Bayes risk, variance of hypothesis length, gradient of entropy and Bayes risk, covariance and Hessian matrix. It's beautifully simple: they recast the quantities of interest as semirings and run the inside (or inside-outside) algorithm. As an example application, they perform minimum risk training on a small Chinese-English task, reporting gains in accuracy. For a related paper on minimum risk techniques, see the poster by Pauls et al.
Novel Modeling and Learning Approaches
Tromble & Eisner also connect translation to theory by way of a novel model, framing reordering as an instance of the linear ordering problem: given a matrix of pairwise ordering preferences between all words in a sentence, can we find a permutation that optimizes the global score? This is NP-hard, but they give a reasonable approximation based on ITG, with some clever dynamic programming tricks to make it work. Then they show how to learn the matrix and use it to reorder test sentences prior to translation, improving over the lexicalized reordering model of Moses on German-English.
However, most of the new models at EMNLP are syntax-based. In the last few years, syntax-based modeling has focused primarily on variants of synchronous context-free grammar (SCFG). This year there's a lot of work investigating more expressive formalisms.
Two papers model translation with restricted variants of synchronous tree-adjoining grammar (STAG). Carreras & Collins model syntax atop phrase pairs with a parser using sister adjunction (as in their 2008 parser). The model resembles a synchronous version of Markov grammar, which also connects it to recent dependency models of translation (e.g. Shen et al. 2008, Galley et al. 2009, Gimpel & Smith below, and Hassan et al. in the poster session). Decoding is NP-complete, and devising efficient beam search is a key point in the paper. The resulting system outperforms Pharaoh on German-English. DeNeefe & Knight model target-side syntax via synchronous tree insertion grammar (STIG). It's similar to synchronous tree substitution grammar (STSG; previously realized in MT as GHKM) with added left- and right-adjunction operations to model optional arguments. They show how to reuse a lot of the STSG machinery via a grammar transformation from STIG to STSG, and the results improve on a strong Arabic-English baseline.
Gimpel & Smith use a relatively new formalism: quasi-synchronous dependency grammar (QDG). In quasi-synchronous grammar, the generation of a target syntax tree is conditioned on (but not necessarily isomorphic to) a source syntax tree. Formally, each target node can be annotated with any source node. Since in dependency grammar the nodes are words, their QDG model resembles a word-to-word model. Decoding with QDG was not obvious given past work, and is one of several novel contributions of the paper. Another is the idea that all possible biphrases can fire an associated feature, regardless of overlap. Kääriäinen makes this idea central. Instead of reasoning over the latent derivations of a generative model, his model directly optimizes a feature-based representation of the target sentence, where the features consist of any biphrase in the training set (per standard heuristics). This raises some new problems -- such as how to find the target sentence given the optimal feature vector -- which are solved with dynamic programming. The decoder doesn't quite beat Moses when used with a language model, but it's an order of magnitude faster!
Three other papers operate on STSG models, with an emphasis on learning techniques. Cohn & Blunsom reformulate tree-to-string STSG induction as a problem in non-parametric Bayesian inference, extending their TSG model for monolingual parsing, and removing the dependence on heuristics over noisy GIZA++ word alignments. The model produces more compact rules, and outperforms GHKM on a Chinese-English task. This is a hot topic: check out Liu & Gildea's poster for an alternative Bayesian formulation of the same problem and language pair. Galron et al. look at tree-to-tree STSG (from a Data-Oriented Parsing perspective), with an eye towards discriminatively learning STSG rules to optimize for translation accuracy.
Bayesian inference also figures in the model of Chung & Gildea, who aim at bilingually-informed segmentation of a source language. The model is like IBM Model 1, except that the source positions are actually substrings of the source instead of single positions. Reasoning over the substring boundaries makes it resemble an HMM, and they use a sparse prior to avoid overfitting. Tokenizing new text uses the marginal distribution on source language segmentations, and this performs almost as well as a supervised segmenter on Chinese, and better on Korean, in end-to-end translation.
SCFG models aren't completely forgotten: Zhang & Li offer a new twist on reordering in binary-branching SCFG. Given a source parse, we could train a maximum entropy classifier to decide whether any binary production should be inverted; this requires a lot of computation over sparse vectors. They instead represent the features implicitly using a tree convolution kernel, showing nice gains in Chinese-English.
On the algorithmic side, Levenberg & Osborne look at language modeling under the condition that we have unbounded data streams in both source and target language, bounded computation, and the desire to bias our language model towards more recent language use without constantly retraining it. They accomplish this with online perfect hashing (extending previous work) in a succinct data structure that supports deletions, showing that they can draw on recent information in both the source and the target to incrementally update the model while keeping a bounded memory footprint.
Bai et al. focus on the problem of acquiring multiword expressions (i.e. idioms), showing why typical word alignment methods fail, and using a combination of statistical association measures and heuristics to fix the problem, with small gains in Chinese-English.
Decoding
Since SCFG models have become mainstream, there's been a greater emphasis on decoding. Following a recent strand of research on grammar transformations for SCFG, Xiao et al. observe that, in the space of possible transformations, many will pair source yields with huge numbers of target yields, which compete during decoding and thus result in more search errors. The trick is to select a transform that distributes target yields more evenly across source yields. They pose this as an optimization problem and give a greedy algorithm; the resulting grammar is reliably better under a variety of conditions on a Chinese-English task. Meanwhile, Zhang et al. engineer more efficient STSG decoding for the case in which the source is a parse forest and source units are tree fragments. The trick is to encode translation rules in the tree path equivalent of a prefix tree. On Chinese-English this improves decoding speed and ultimately translation accuracy, because the decoder can consider larger fragments much more efficiently. Finally, see Finch & Sumita's comprehensive poster on bidirectional phrase-based decoding for a huge number of language pairs.
Onwards and Upwards
The align/extract/MERT pipeline popularized by Moses and other NIST-style systems is incredibly hard to improve, but several papers manage just that.
Hermjakob's word aligner starts from lexical translation parameters learned by a statistical alignment model. Then, following some fairly general observations on different linguistic classes of words, it uses some well-motivated heuristics to fix a whole bunch of little things that many more principled models ignore: the different behavior of content words (improved via careful manipulation of pointwise mutual information) and function words (improved via constraints from parse structure) is treated along with careful handling of numbers, transliterations, and morphology to give strong improvements in Arabic-English.
Liu et al. then extract phrases by relaxing standard heuristic constraints. Given a posterior probability for every alignment point, they simply calculate the probability that a phrase would be extracted, and use this as their count in the typical frequency-based estimate. It's efficient and improves Chinese-English.
Three papers incorporate new feature types into strong baseline translation models, following a recent trend. Shen et al. devise some clever local features using source-side context, derivation span length, and dependency modeling to make impressive improvements on an already impressive baseline system in both Chinese-English and Arabic-English. Matsoukas et al. then show how a mixed-genre system can effectively be adapted for a particular target domain, by using a small amount data to tune weights tied to genre and collection types in the training corpus, again with strong results in Arabic-English. Mauser et al. take their previous triplet lexicon model (a probabilistic feature using an outside source word as additional conditioning context) and move it from a reranking step into the decoding step, with a nice experimental treatment showing improvements in large-scale Chinese-English and Arabic-English.
If you've seen the latest NIST results, you know that system combination gives huge improvements. Check out posters by He & Toutanova, Duan et al., and Feng et al. to learn the latest techniques. Last but not least, if you need a strategy for language pairs with very little parallel data, the poster by Nakov & Ng will interest you.
Thanks
EMNLP was the first time I've been area chair for a conference, and it was really rewarding to work with such great volunteers and< to see the great papers that were selected (I should note here that I included two papers not on my track that I'm quite familiar with -- the ones from Edinburgh). It was also very enlightening, but that's another story. Many thanks to Hal for offering this forum to share the results!
01 August 2009
Destination: Singapore
Welcome to everyone to ACL! It's pretty rare for me to end up conferencing in a country I've been before, largely because I try to avoid it. When I was here last time, I stayed with Yee Whye, who was here at the time as a postdoc at NUS, and lived here previously in his youth. As a result, he was an excellent "tour guide." With his help, here's a list of mostly food related stuff that you should definitely try while here (see also the ACL blog):
- Pepper crab. The easiest to find are the "No Signboard" restaurant chain. Don't wear a nice shirt unless you plan on doing laundry.
- Chicken rice. This sounds lame. Sure, chicken is kind of tasty. Rice is kind of tasty. But the key is that the rice is cooked in or with melted chicken fat. It's probably the most amazingly simple and delicious dish I've ever had. "Yet Kun" (or something like that) is along Purvis street.
- Especially for dessert, there's Ah Chew, a Chinese place around Liang Seah street in the Bugis area (lots of other stuff there too).
- Hotpot is another local specialty: there is very good spicy Szechuan hotpot around Liang Seah street.
- For real Chinese tea, here. (Funny aside: when I did this, they first asked "have you had tea before?" Clearly the meaning is "have you had real Chinese tea prepared traditionally and tasted akin to a wine tasting?" But I don't think I would ever ask someone "have you had wine before?" But I also can't really think of a better way to ask this!)
- Good late night snacks can be found at Prata stalls (eg., indian roti with curry).
- The food court at Vivocity, despite being a food court, is very good. You should have some hand-pressed sugar cane juice -- very sweet, but very tasty (goes well with some spicy hotpot).
- Chinatown has good Chinese dessert (eg., bean stuff) and frog leg porridge.
Now, I realize that most of the above list is not particularly friendly to my happy cow friends. Here's a list of restaurants that happy cow provides. There are quite a few vegetarian options, probably partially because of the large Muslim population here. There aren't as many vegan places, but certainly enough. For the vegan minded, there is a good blog about being vegan in Singapore (first post is about a recent local talk by Campbell, the author of The China Study, which I recommend everyone at least reads). I can't vouch for the quality of these places, but here's a short list drawn from Living Vegan:
- Mushroom hotpot at Ling Zhi
- Fried fake meat udon noodles (though frankly I'm not a big fan of fake meat)
- Green Pasture cafe; looks like you probably have to be a bit careful here in terms of what you order
- Yes Natural; seems like it has a bunch of good options
- Lotus Veg restaurant, seems to have a bunch of dim sum (see here, too)
- If you must, there's pizza
- And oh-my-gosh, there's actually veggie chicken rice, though it doesn't seem like it holds up to the same standards as real chicken rice (if it did, that would be impressive)
Enjoy your time here!
Quick update: Totally forgot about coffee. If you need your espresso kick, Highlander coffee (49 Kampong Bahru Road) comes the most recommended, but is a bit of a hike from the conference area. Of course, you could also try the local specialty: burnt crap with condensed milk (lots and lots of discussion especially on page two here).
21 July 2009
Non-parametric as memorizing, in exactly the wrong way?
There is a cool view of the whole non-parametric Bayes thing that I think is very instructive. It's easiest to see in the case of the Pitman-Yor language modeling work by Frank Wood and Yee Whye Teh. The view is "memorize what you can, and back off (to a parametric model) when you can't." This is basically the "backoff" view... where NP Bayes comes in is to control the whole "what you can" aspect. In other words, if you're doing language modeling, try to memorize two grams; but if you haven't seen enough to be confident in your memorization, back off to one grams; and if you're not confident there, back off to a uniform distribution (which is our parametric model -- the base distribution).
Or, if you think about the state-splitting PCFG work (done both at Berkeley and at Stanford), basically what's going on is that we're memorizing as many differences of tree labels as we can, and then backing off to the "generic" label when memorization fails. Or if we look at Trevor Cohn's NP-Bayes answer to DOP, we see a similar thing: memorize big tree chunks, but if you can't, fall back to a simple CFG (our parametric model).
Now, the weird thing is that this mode of memorization is kind of backwards from how I (as an outsider) typically interpret cognitive models (any cogsci people out there, feel free to correct me!). If you take, for instance, morphology, there's evidence that this is exactly not what humans do. We (at least from a popular science) perspective, basically memorize simple rules and then remember exceptions. That is, we remember that to make the past tense of a verb, we add "-ed" (the sound, not the characters) but for certain verbs, we don't: go/went, do/did, etc. You do little studies where you ask people to inflect fake words and they generally follow the rule, not the exceptions (but see * below).
If NP Bayes had its way on this problem (or at least if the standard models I'm familiar with had their way), they would memorize "talk" -> "talked" and "look" -> "looked" and so on because they're so familiar. Sure, it would still memorize the exceptions, but it would also memorize the really common "rule cases too... why? Because of course it could fall back to the parametric model, but these are so common that the standard models would really like to take advantage of the rich-get-richer phenomenon on things like DPs, thus saving themselves cost by memorizing a new "cluster" for each common word. (Okay, this is just my gut feeling about what such models would do, but I think it's at least defensible.) Yes, you could turn the DP "alpha" parameter down, but I guess I'm just not convinced this would do the right thing. Maybe I should just implement such a beast but, well, this is a blog post, not a *ACL paper :P.
Take as an alternative example the language modeling stuff. Basically what it says is "if you have enough data to substantiate memorizing a 5 gram, you should probably memorize a 5 gram." But why? If you could get the same effect with a 2 or 3 gram, why waste the storage/time?!
I guess you could argue "your prior is wrong," which is probably true for most of these models. In which case I guess the question is "what prior does what I want?" I don't have a problem with rich get richer -- in fact, I think it's good in this case. I also don't have a problem with a logarithmic growth rate in the number of exceptions (though I'd be curious how this holds up empirically -- in general, I'm a big fan of checking if your prior makes sense; for instance, Figure 3 (p16) of my supervised clustering paper). I just don't like the notion of memorizing when you don't have to.
(*) I remember back in grad school a linguist from Yale came and gave a talk at USC. Sadly, I can't remember who it was: if anyone wants to help me out, I'd really appreciate it! The basic claim of the talk is that humans actually memorize a lot more than we give them credit for. The argument was in favor of humans basically memorizing all morphology and not backing off to rules like "add -ed." One piece of evidence in favor of this was timing information for asking people to inflect words: the timing seemed to indicate a linear search through a long list of words that could possibly be inflected. I won't say much more about this because I'm probably already misrepresenting it, but it's an interesting idea. And, if true, maybe the NP models are doing exactly what they should be doing!
05 July 2009
Small changes beget good or bad examples?
If you compare vision research with NLP research, there are a lot of interesting parallels. Like we both like linear models. And conditional random fields. And our problems are a lot harder than binary classification. And there are standard data sets that we've been evaluating on for decades and continue to evaluate on (I'm channeling Bob here :P).
But there's one thing that happens, the difference of which is so striking, that I'd like to call it to center stage. It has to do with "messing with our inputs."
I'll spend a bit more time describing the vision approach, since it's probably less familiar to the average reader. Suppose I'm trying to handwriting recognition to identify digits from zero to nine (aka MNIST). I get, say, 100 labeled zeros, 100 labeled ones, 100 labeled twos and so on. So a total of 1000 data points. I can train any off the shelf classifier based on pixel level features and get some reasonable performance (maybe 80s-90s, depending).
Now, I want to insert knowledge. The knowledge that I want to insert is some notion of invariance. I.e., if I take an image of a zero and translate it left a little bit, it's still a zero. Or up a little bit. Of if I scale it up 10%, it's still a zero. Or down 10%. Or if I rotate it five degrees. Or negative five. All zeros. Same hold for all the other digits.
One way to insert this knowledge is to muck with the learning algorithm. That's too complicated for me: I want something simpler. So what I'll do is take my 100 zeros and 100 ones and so on and just manipulate them a bit. That is, I'll sample a random zero, and apply some small random transformations to it, and call it another labeled example, also a zero. Now I have 100,000 training points. I train my off the shelf classifier based on pixel level features and get 99% accuracy or more. The same trick works for other vision problem (eg., recognizing animals). (This process is so common that it's actually described in Chris Bishop's new-ish PRML book!)
This is what I mean by small changes (to the input) begetting good example. A slightly transformed zero is still a zero.
Of course, you have to be careful. If you rotate a six by 180 degrees, you get a nine. If you rotate a cat by 180 degrees, you get an unhappy cat. More seriously, if you're brave, you might start looking at a class of transformations called diffeomorphisms, which are fairly popular around here. These are nice because of their nice mathematical properties, but un-nice because they can be slightly too flexible for certain problems.
Now, let's go over to NLP land. Do we ever futz with our inputs?
Sure!
In language modeling, we'll sometimes permute words or replace one word with another to get a negative example. Noah Smith futzed with his inputs in contrastive estimation to produce negative examples by swapping adjacent words, or deleting words.
In fact, try as I might, I cannot think of a single case in NLP where we make small changes to an input to get another good input: we always do it to get a bad input!
In a sense, this means that one thing that vision people have that we don't have is a notion of semantics preserving transformations. Sure, linguists (especially those from that C-guy) study transformations. And there's a vague sense that work in paraphrasing leads to transformations that maintain semantic equivalence. But the thing is that we really don't know any transformations that preserve semantics. Moreover, some transformations that seem benign (eg., passivization) actually are not: one of my favorite papers at NAACL this year by Greene and Resnik showed that syntactic structure affects sentiment (well, them, drawing on a lot of psycholinguistics work)!
I don't have a significant point to this story other than it's kind of weird. I mentioned this to some people at ICML and got a reaction that replacing words with synonyms should be fine. I remember doing this in high school, when word processors first started coming with thesauri packed in. The result seemed to be that if I actually knew the word I was plugging in, life was fine... but if not, it was usually a bad replacement. So this seems like something of a mixed bag: depending on how liberal you are with defining "synonym" you might be okay do this, but you might also not be.
30 June 2009
ICML/COLT/UAI 2009 retrospective
This will probably be a bit briefer than my corresponding NAACL post because even by day two of ICML, I was a bit burnt out; I was also constantly swapping in other tasks (grants, etc.). Note that John has already posted his list of papers.
- #317: Multi-View Clustering via Canonical Correlation Analysis (Chaudhuri, Kakade, Livescu, Sridharan). This paper shows a new application of CCA to clustering across multiple views. They use some wikipedia data in experiments and actually prove something about the fact that (under certain multi-view-like assumptions), CCA does the "right thing."
- #295: Learning Nonlinear Dynamic Models (Langford, Salakhutdinov,, Zhang). The cool idea here is to cut a deterministic classifier in half and use its internal state as a sort of sufficient statistic. Think about what happens if you represent your classifier as a circuit (DAG); then anywhere you cut along the circuit gives you a sufficient representation to predict. To avoid making circuits, they use neural nets, which have an obvious "place to cut" -- namely, the internal nodes.
- #364: Online Dictionary Learning for Sparse Coding (Mairal, Bach, Ponce, Sapiro). A new approach to sparse coding; the big take-away is that it's online and fast.
- 394: MedLDA: Maximum Margin Supervised Topic Models for Regression and Classification (Zhu, Ahmed, Xing). This is a very cute idea for combining objectives across topic models (namely, the variational objective) and classification (the SVM objective) to learn topics that are good for performing a classification task.
- #393: Learning from Measurements in Exponential Families (Liang, Jordan, Klein). Suppose instead of seeing (x,y) pairs, you just see some statistics on (x,y) pairs -- well, you can still learn. (In a sense, this formalizes some work out of the UMass group; see also the Bellare, Druck and McCallum paper at UAI this year.)
- #119: Curriculum Learning (Bengio, Louradour, Collobert, Weston). The idea is to present examples in a well thought-out order rather than randomly. It's a cool idea; I've tried it in the context of unsupervised parsing (the unsearn paper at ICML) and it never helped and often hurt (sadly). I curriculum-ified by sentence length, though, which is maybe not a good model, especially when working with WSJ10 -- maybe using vocabulary would help.
- #319: A Stochastic Memoizer for Sequence Data (Wood, Archambeau, Gasthaus, James, Whye Teh). If you do anything with Markov models, you should read this paper. The take away is: how can I learn a Markov model with (potentially) infinite memory in a linear amount of time and space, and with good "backoff" properties. Plus, there's some cool new technology in there.
- A Uniqueness Theorem for Clustering Reza Bosagh Zadeh, Shai Ben-David. I already talked about this issue a bit, but the idea here is that if you fix k, then the clustering axioms become satisfiable, and are satisfied by two well known algorithms. Fixing k is a bit unsatisfactory, but I think this is a good step in the right direction.
- Convex Coding David Bradley, J. Andrew Bagnell. The idea is to make coding convex by making it infinite! And then do something like boosting.
- On Smoothing and Inference for Topic Models Arthur Asuncion, Max Welling, Padhraic Smyth, Yee Whye Teh. If you do topic models, read this paper: basically, none of the different inference algorithms do any better than the others (perplexity-wise) if you estimate hyperparameters well. Come are, of course, faster though.
- Correlated Non-Parametric Latent Feature Models Finale Doshi-Velez, Zoubin Ghahramani. This is an indian-buffet-process-like model that allows factors to be correlated. It's somewhat in line with our own paper from NIPS last year. There's still something a bit unsatisfactory in both our approach and their approach that we can't do this "directly."
- Domain Adaptation: Learning Bounds and Algorithms. Yishay Mansour, Mehryar Mohri and Afshin Rostamizadeh. Very good work on some learning theory for domain adaptation based on the idea of stability.
25 June 2009
Should there be a shared task for semi-supervised learning in NLP?
(Guest post by Kevin Duh. Thanks, Kevin!)
At the NAACL SSL-NLP Workshop recently, we discussed whether there ought to be a "shared task" for semi-supervised learning in NLP. The panel discussion consisted of Hal Daume, David McClosky, and Andrew Goldberg as panelists and audience input from Jason Eisner, Tom Mitchell, and many others. Here we will briefly summarize the points raised and hopefully solicit some feedback from blog readers.
Three motivations for a shared task
A1. Fair comparison of methods: A common dataset will allow us to compare different methods in an insightful way. Currently, different research papers use different datasets or data-splits, making it difficult to draw general intuitions from the combined body of research.
A2. Establish a methodology for evaluating SSLNLP results: How exactly should a semi-supervised learning method be evaluated? Should we would evaluate the same method for both low-resource scenarios (few labeled points, many unlabeled points) and high-resource scenarios (many labeled points, even more unlabeled points)? Should we evaluate the same method under different ratios of labeled/unlabeled data? Currently there is no standard methodology for evaluating SSLNLP results, which means that the completeness/quality of experimental sections in research papers varies considerably.
A3. Encourage more research in the area: A shared task can potentially lower the barrier of entry to SSLNLP, especially if it involves pre-processed data and community support network. This will make it easier for researchers in outside fields, or researchers with smaller budgets to contribute their expertise to the field. Furthermore, a shared task can potentially direct the community research efforts in a particular subfield. For example, "online/lifelong learning for SSL" and "SSL as joint inference of multiple tasks and heterogeneous labels" (a la Jason Eisner's keynote) were identified as new, promising areas to focus on in the panel discussion. A shared task along those lines may help us rally the community behind these efforts.
Arguments against the above points
B1. Fair comparison: Nobody really argues against fair comparison of methods. The bigger question, however, is whether there exist a *common* dataset or task where everyone is interested in. At the SSLNLP Workshop, for example, we had papers in a wide range of areas ranging from information extraction to parsing to text classification to speech. We also had papers where the need for unlabeled data is intimately tied in to particular components of a larger system. So, a common dataset is good, but what dataset can we all agree upon?
B2. Evaluation methodology: A consistent standard for evaluating SSLNLP results is nice to have, but this can be done independently from a shared task through, e.g. an influential paper or gradual recognition of its importance by reviewers. Further, one may argue: what makes you think that your particular evaluation methodology is the best? What makes you think people will adopt it generally, both inside and outside of the shared task?
B3. Encourage more research: It is nice to lower the barriers to entry, especially if we have pre-processed data and scripts. However, it has been observed in other shared tasks that often it is the pre-processing and features that matter most (more than the actual training algorithm). This presents a dilemma: If the shared task pre-processes the data to make it easy for anyone to join, will we lose the insights that may be gained via domain knowledge? On the other hand, if we present the data in raw form, will this actually encourage outside researchers to join the field?
Rejoinder
A straw poll at the panel discussion showed that people are generally in favor of looking into the idea of a shared task. The important question is how to make it work, and especially how to address counterpoints B1 (what task to choose) and B3 (how to prepare the data). We did not have enough time during the panel discussion to go through the details, but here are some suggestions:
- We can view NLP problems as several big "classes" of problems: sequence prediction, tree prediction, multi-class classification, etc. In choosing a task, we can pick a representative task in each class, such as name-entity recognition for sequence prediction, dependency parsing for tree prediction, etc. This common dataset won't attract everyone in NLP, but at least it will be relevant for a large subset of researchers.
- If participants are allowed to pre-process their own data, the evaluation might require participant to submit a supervised system along with their semi-supervised system, using the same feature set and setup, if possible. This may make it easier to learn from results if there are differences in pre-processing.
- There should also be a standard supervised and semi-supervised baseline (software) provided by the shared task organizer. This may lower the barrier of entry for new participants, as well as establish a common baseline result.
20 June 2009
Why I Don't Buy Clustering Axioms
In NIPS 15, Jon Kleinberg presented some impossibility results for clustering. The idea is to specify three axioms that all clustering functions should obey and examine those axioms.
Let (X,d) be a metric space (so X is a discrete set of points and d is a metric over the points of X). A clustering function F takes d as input and produces a clustering of the data. The three axioms Jon states that all clustering functions should satisfy are:
- Scale invariance: For all d, for all a>0, F(ad) = F(d). In other words, if I transform all my distances by scaling them uniformly, then the output of my clustering function should stay the same.
- Richness: The range of F is the set of all partitions. In other words, there isn't any bias that prohibits us from producing some particular partition.
- Consistency: Suppose F(d) gives some clustering, C. Now, modify d by shrinking distances within clusters of C and expanding distances between clusters in C. Call the new metric d'. Then F(d') = C.
If you think about these axioms a little bit, they kind of make sense. My problem is that if you think about them a lot of bit, you (or at least I) realize that they're broken. The biggest broken one is consistency, which becomes even more broken when combined with scale invariance.
What I'm going to do to convince you that consistency is broken is start with some data in which there is (what I consider) a natural clustering into two clusters. I'll then apply consistency a few times to get something that (I think) should yield a different clustering.
Let's start with some data. The colors are my opinion as to how the data should be clustered:
 I hope you agree with my color coding. Now, let's apply consistency. In particular, let's move some of the red points, only reducing inter-clustering distances. Formally, we find the closest pair of points and move things toward those.
I hope you agree with my color coding. Now, let's apply consistency. In particular, let's move some of the red points, only reducing inter-clustering distances. Formally, we find the closest pair of points and move things toward those. The arrows denote the directions these points will be moved. To make the situation more visually appealing, let's move things into lines:
The arrows denote the directions these points will be moved. To make the situation more visually appealing, let's move things into lines: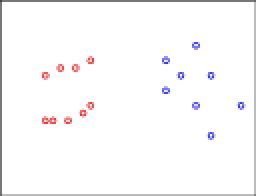 Okay, this is already looking funky. Let's make it even worse. Let's apply consistency again and start moving some blue points:
Okay, this is already looking funky. Let's make it even worse. Let's apply consistency again and start moving some blue points: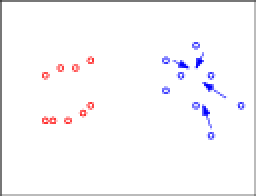 Again, let's organize these into a line:
Again, let's organize these into a line: And if I had given you this data to start with, my guess is the clustering you'd have come up with is more like:
And if I had given you this data to start with, my guess is the clustering you'd have come up with is more like: This is a violation of consistency.
This is a violation of consistency.So, what I'd like someone to do is to argue to my why consistency is actually a desirable property.
I can come up with lots of other examples. One reason why this invariance is bad is because it renders the notion of "reference sizes" irrelevant. This is of course a problem if you have prior knowledge (eg., one thing measured in millimeters, the other in kilometers). But even in the case where you don't know knowledge, what you can do is take the following. Take data generated by thousands of well separated Gaussians, so that the clearly right thing to do is have one cluster per Gaussian. Now, for each of these clusters except for one, shrink them down to single points. This is possible by consistency. Now, your data basically looks like thousands-1 of clusters with zero inter-cluster distances and then one cluster that's spread out. But now it seems that the reasonable thing is to put each data point that was in this old cluster into its own cluster, essentially because I feel like the other data shows you what clusters should look like. If you're not happy with this, apply scaling and push these points out super far from each other. (I don't think this example is as compelling as the one I drew in pictures, but I still think it's reasonable.
Now, in the UAI paper this year, they show that if you fix the number of clusters, these axioms are now consistent. (Perhaps this has to do with the fact that all of my "weird" examples change the number of clusters -- though frankly I don't think this is necessary... I probably could have arranged it so that the resulting green and blue clusters look like a single line that maybe should just be one cluster by itself.) But I still feel like consistency isn't even something we want.
(Thanks to the algorithms group at Utah for discussions related to some of these issues.)
UPDATE 20 JUNE 2009, 3:49PM EST
Here's some data to justify the "bad things happen even when the number of clusters stays the same" claim.
Start with this data:

Now, move some points toward the middle (note they have to spread to the side a bit so as not to decrease intra-cluster distances).

Yielding data like the following:

Now, I feel like two horizontal clusters are most natural here. But you may disagree. What if I add some more data (ie., this is data that would have been in the original data set too, where it clearly would have been a third cluster):

And if you still disagree, well then I guess that's fine. But what if there were hundreds of other clusters like that.
I guess the thing that bugs me is that I seem to like clusters that have similar structures. Even if some of these bars were rotated arbitrarily (or, preferably, in an axis-aligned manner), I would still feel like there's some information getting shared across the clusters.
14 June 2009
NL Generation: A new problem
Those who talk to me a lot over the years know that I really think that generation is a cool and interesting problem, but one that is hampered by a lack of clarity of what it is, or at least what the input/output is. It's like the problem with defining summarization, but one hundred times worse.
I have no idea how it came up. I think I was talking to a bunch of people from Microsoft Research and we were talking about translation on the web and what not. And how this is not the business model of Language Weaver. And how when you're on the web you make money by advertising.
And voila! The most incredible NL Generation task occurred to me! (I apologize if you ran in to me at all during NAACL because this was pretty much all I could talk about :P.) The initial idea for the task was embedded in MT, though it needn't be. But I'll tell it in the MT setting.
So I go to some web page in some weirdo language (say, French) that I don't understand (because I was a moron and took Latin instead of French or Spanish in middle school and high school). So I ask my favorite translation system (Google or Microsoft or Babelfish or whatever) to translate it. However, the translation system takes certain liberties with the translation. In particular, it might embed a few "product placements" in the text. For instance, maybe it's translating "Je suis vraiment soif" into English (if this is incorrect, blame Google). And perhaps it decides that instead of translating this as "I'm really thirsty," it will translate it as "I'm really thirsty for a Snapple," or "I'm really thirsty: I could go for a Snapple," perhaps with a link to snapple.com.
Product placement is all over the place, even in America where it's made fun of and kept a bit at bay. Not so in China: any American remotely turned off by the Coca-cola cups from which the judges on American Idol drink twice a week would be appalled by the ridiculous (my sentiment) product placement that goes on over there. The presence of the link would probably give away that it's an ad, though of course you could leave this off.
But why limit this to translation. You could put such a piece of technology directly on blogger, or on some proxy server that you can go through to earn some extra cash browsing the web (thanks to someone -- can't remember who -- at NAACL for this latter suggestion). I mean, you could just have random ads pop up in the middle of text on any web page, for instance one you could host on webserve.ca!
(See what I did there?)
So now here's a real generation problem! You're given some text. And maybe you're even given adwords or something like that, so you can assume that the "select which thing to advertise" problem has been solved. (Yes, I know it's not.) Your job is just to insert the ad in the most natural way in the text. You could evaluate in at least two ways: click through (as is standard in a lot of this advertising business) and human judgments of naturalness. I think the point of product placement is to (a) get your product on the screen more or less constantly, rather than just during commercial breaks which most people skip anyway, and (b) perhaps appeal to people's subconscious. I don't know. My parents (used to) do advertising like things but I know next to nothing about that world.
Okay, so this is slightly tongue in cheek, but not entirely. And frankly, I wouldn't be surprised if something like it were the norm in five years. (If you want to get more fancy, insert product placements into youtube videos!)
12 June 2009
NAACL-HLT 2009 Retrospective
I hope this post will be a small impetus to get other people to post comments about papers they saw at NAACL (and associated workshops) that they really liked.
As usual, I stayed for the whole conference, plus workshops. As usual, I also hit that day -- about halfway through the first workshop day -- where I was totally burnt out and was wondering why I always stick around for the entire week. That's not to say anything bad about the workshops specifically (there definitely were good ones going on, in fact, see some comments below), but I was just wiped.
Anyway, I saw a bunch of papers and missed even more. I don't think I saw any papers that I actively didn't like (or wondered how they got in), including short papers, which I think is fantastic. Many thanks to all the organizers (Mari Ostendorf for organizing everything, Mike Collins, Lucy Vanderwende, Doug Oard and Shri Narayanan for putting together a great program, James Martin and Martha Palmer for local arrangements -- which were fantastic -- and all the other organizers who sadly we -- i.e., the NAACL board -- didn't get a chance to thank publicly).
Here are some things I thought were interesting:
- Classifier Combination Techniques Applied to Coreference Resolution (Vemulapalli, Luo, Pitrelli and Zitouni). This was a student research workshop paper; in fact, it was the one that I was moderating (together with Claire Cardie). The student author, Smita, performed this work while at IBM; though her main research is on similar techniques applied to really cool sounding problems in recognizing stuff that happens in the classroom. Somehow classifier combination, and general system combination, issues came up a lot at this conference (mostly in the hallways where someone was begrudgingly admitting to working on something as dirty as system combination). I used to think system combination was yucky, but I don't really feel that way anymore. Yes, it would be nice to have one huge monolithic system that does everything, but that's often infeasible. My main complaint with system combination stuff is that in many cases I don't really understand why it's helping, which means that unless it's applied to a problem I really care about (of which there are few), it's hard for me to take anything away. But I think it's interesting. Getting back to Smita's paper, the key thing she did to make this work is introduce the notion of alignments between different clusterings, which seemed like a good idea. The results probably weren't as good as they were hoping for, but still interesting. My only major pointers as a panelist were to try using different systems, rather than bootstrapped versions of the same system, and to take a look at the literature on consensus clustering, which is fairly relevant for this problem.
- Graph-based Learning for Statistical Machine Translation (Alexandrescu and Kirchhoff). I'd heard of some of this work before in small group meetings with Andrei and Kathrin, but this is the first time I'd seen the results they presented. This is an MT paper, but really it's about how to do graph-based semi-supervised learning in a structured prediction context, when you have some wacky metric (read: BLEU) on which you're evaluating. Computation is a problem, but we should just hire some silly algorithms people to figure this out for us. (Besides, there was a paper last year at ICML -- I'm too lazy to dig it up -- that showed how to do graph-based stuff on billions of examples.)
- Intersecting Multilingual Data for Faster and Better Statistical Translations (Chen, Kay and Eisele). This is a very simple idea that works shockingly well. Had I written this paper, "Frustrating" would probably have made it into the title. Let's say we want an English to French phrase table. Well, we do phrase table extraction and we get something giant and ridiculous (have you ever looked at those phrase pairs) that takes tons of disk space and memory, and makes translation slow (it's like the "grammar constant" in parsing that means that O(n^3) for n=40 is impractical). Well, just make two more phrase tables, English to German and German to French and intersect. And viola, you have tiny phrase tables and even slightly better performance. The only big caveat seems to be that they estimate all these things on Europarl. What if your data sets are disjoint: I'd be worried that you'd end up with nothing in the resulting phrase table except the/le and sometimes/quelquefois (okay, I just used that example because I love that word).
- Quadratic Features and Deep Architectures for Chunking (Turian, Bergstra and Bengio). I definitely have not drunk the deep architectures kool-aid, but I still think this sort of stuff is interesting. The basic idea here stems from some work Bergstra did for modeling vision, where they replaced a linear classifier(y = w'x) with a low rank approximation to a quadratic classifier (y = w'x + sqrt[(a'x)^2 + (b'x)^2 + ... ]). Here, the a,b,... vectors are all estimated as part of the learning process (eg., by stochastic gradient descent). If you use a dozen of them, you get some quadratic style features, but without the expense of doing, say, an implicit (or worse, explicit) quadratic kernel. My worry (that I asked about during the talk) is that you obviously can't initialize these things to zero or else you're in a local minimum, so you have to do some randomization and maybe that makes training these things a nightmare. Joseph reassured me that they have initialization methods that make my worries go away. If I have enough time, maybe I'll give it a whirl.
- Exploring Content Models for Multi-Document Summarization (Haghighi and Vanderwende). This combines my two favorite things: summarization and topic models. My admittedly biased view was they started with something similar to BayeSum and then ran a marathon. There are a bunch of really cool ideas in here for content-based summarization.
- Global Models of Document Structure using Latent Permutations (Chen, Branavan, Barzilay and Karger). This is a really cool idea (previously mentioned in a comment on this blog) based on using generalized Mallow's models for permutation modeling (incidentally, see a just-appeared JMLR paper for some more stuff related to permutations!). The idea is that documents on a similar topic (eg., "cities") tend to structure their information in similar ways, which is modeled as a permutation over "things that could be discussed." It's really cool looking, and I wonder if something like this could be used in conjunction with the paper I talk about below on summarization for scientific papers (9, below). One concern raised during the questions that I also had was how well this would work for things not as standardized as cities, where maybe you want to express preferences of pairwise ordering, not overall permutations. (Actually, you can do this, at least theoretically: a recent math visitor here, Mark Huber, has some papers on exact sampling from permutations under such partial order constraints using coupling from the past.) The other thing that I was thinking during that talk that I thought would be totally awesome would be to do a hierarchical Mallow's model. Someone else asked this question, and Harr said they're thinking about this. Oh, well... I guess I'm not the only one :(.
- Dan Jurafsky's invited talk was awesome. It appealed to me in three ways: as someone who loves language, as a foodie, and as an NLPer. You just had to be there. I can't do it justice in a post.
- More than Words: Syntactic Packaging and Implicit Sentiment (Greene and Resnik). This might have been one of my favorite papers of the conference. The idea is that how you say things can express your point of view as much as what you say. They look specifically at effects like passivization in English, where you might say something like "The truck drove into the crowd" rather than "The soldier drove the truck into the crowd." The missing piece here seems to be identifying the "whodunnit" in the first sentence. This is like figuring out subjects in languages that like the drop subjects (like Japanese). Could probably be done; maybe it has been (I know it's been worked on in Japanese; I don't know about English).
- Using Citations to Generate Surveys of Scientific Paradigms (Mohammad, Dorr, Egan, Hassan, Muthukrishan, Qazvinian, Radev and Zajic). I really really want these guys to succeed. They basically study how humans and machines create summaries of scientific papers when given either the text of the paper, or citation snippets to the paper. The idea is to automatically generate survey papers. This is actually an area I've toyed with getting in to for a while. The summarization aspect appeals to me, and I actually know and understand the customer very well. The key issue I would like to see addressed is how these summaries vary across different users. I've basically come to the conclusion that in summarization, if you don't pay attention to the user, you're sunk. This is especially true here. If I ask for a summary of generalization bound stuff, it's going to look very different than if Peter Bartlett asks for it.
- Online EM for Unsupervised Models (Liang and Klein). If you want to do online EM read this paper. On the other hand, you're going to have to worry about things like learning rate and batch size (think Pegasos). I was thinking about stuff like this a year or two ago and was wondering how this would compare to doing SGD on the log likelihood directly and not doing EM at all. Percy says that asymptotically they're the same, but who knows what they're like in the real world :). I think it's interesting, but I'm probably not going to stop doing vanilla EM.
I spent the first morning in the Computational Approaches to Linguistic Creativity workshop, which was just a lot of fun. I really liked all of the morning talks: if you love language and want to see stuff somewhat off the beaten path, you should definitely read these. I went by the Semantic Evaluation Workshop for a while and learned that the most frequent sense baseline is hard to beat. Moreover, there might be something to this discourse thing after all: Marine tells us that translators don't like to use multiple translations when one will do (akin to the one sense per discourse observation). The biggest question in my head here is how much the direction of translation matters (eg., when this heuristic is violated, is it violated by the translator, or the original author)? Apparently this is under investigation. But it's cool because it says that even MT people shouldn't just look at one sentence at a time!
Andrew McCallum gave a great, million-mile-an-hour invited talk on joint inference in CoNLL. I'm pretty interested in this whole joint inference business, which also played a big role in Jason Eisner's invited talk (that I sadly missed) at the semi-supervised learning workshop. To me, the big question is: what happens if you don't actually care about some of the tasks. In a probabilistic model, I suppose you'd marginalize them out... but how should you train? In a sense, since you don't care about them, it doesn't make sense to have a real loss associated with them. But if you don't put a loss, what are you doing? Again,in probabilistic land you're saved because you're just modeling a distribution, but this doesn't answer the whole question.
Al Aho gave a fantastically entertaining talk in the machine translation workshop about unnatural language processing. How the heck they managed to get Al Aho to give an invited talk is beyond me, but I suspect we owe Dekai some thanks for this. He pointed to some interesting work that I wasn't familiar with, both in raw parsing (eg., how to parse errorfull strings with a CFG when you want to find the closest in edit distance string that is parseable by a CFG) and natural language/programming language interfaces. (In retrospect, the first result is perhaps obvious had I actually thought much about it, though probably not so back in 1972: you can represent edit distance by a lattice and then parse the lattice, which we know is efficient.)
Anyway, there were other things that were interesting, but those are the ones that stuck in my head somehow (note, of course, that this list is unfairly biased toward my friends... what can I say? :P).
So, off to ICML on Sunday. I hope to see many of you there!
09 June 2009
Navigating ICML
I couldn't find a schedule for ICML that had paper titles/authors written in, so I joined the existing schedule with the abstracts to create a printable schedule with titles. You can find organizer-created schedules for UAI and COLT already. In addition, I've put ICML 2009 up on WhatToSee, so have fun! (I haven't done UAI and/or COLT because their papers haven't appeared online yet.)
08 June 2009
The importance of input representations
As some of you know, I run a (machine learning) reading group every semester. This summer we're doing "assorted" topics, which basically means students pick a few papers from the past 24 months that are related and present on them. The week before I went out of town, we read two papers about inferring features from raw data; one was a deep learning approach; the other was more Bayesian. (As a total aside, I found it funny that in the latter paper they talk a lot about trying to find independent features, but in all cog sci papers I've seen where humans list features of objects/categories, they're highly dependent: eg., "has fur" and "barks" are reasonable features that humans like to produce that are very much not independent. In general, I tend to think that modeling things as explicitly dependent is a good idea.)
Papers like this love to use vision examples, I guess because we actually have some understanding of how the visual cortex words (from a neuroscience perspective), which we sorely lack for language (it seems much more complicated). They also love to start with pixel representations; perhaps this is neurologically motivated: I don't really know. But I find it kind of funny, primarily because there's a ton of information hard wired into the pixel representation. Why not feed .jpg and .png files directly into your system?
On the language side, an analogy is the bag of words representation. Yes, it's simple. But only simple if you know the language. If I handed you a bunch of text files in Arabic (suppose you'd never done any Arabic NLP) and asked you to make a bag of words, what would you do? What about Chinese? There, it's well known that word segmentation is hard. There's already a huge amount of information in a bag of words format.
The question is: does it matter?
Here's an experiment I did. I took the twenty newsgroups data (standard train/test split) and made classification data. To make the classification data, I took a posting, fed it through a module "X". "X" produced a sequence of tokens. I then extract n-gram features over these tokens and throw out anything that appears less than ten times. I then train a multiclass SVM on these (using libsvm). The only thing that varies in this setup is what "X" does. Here are four "X"s that I tried:
- Extract words. When composed with extracting n-gram tokens, this leads to a bag of words, bag of bigrams, bag of trigrams, etc., representation.
- Extract characters. This leads to character unigrams, character bigrams, etc.
- Extract bits from characters. That is, represent each character in its 8 bit ascii form and extract a sequence of zeros and ones.
- Extract bits from a gzipped version of the posting. This is the same as (3), but before extracting the data, we gzip the file.
 As we can see, characters do well, even at the same bit sizes. Basically you get a ton of binary sequence features from raw bits that are just confusing the classifier. Zipped bits do markedly worse than raw bits. The reason the bit-based models don't extend further is because it started taking gigantic amounts of memory (more than my poor 32gb machine could handle) to process and train on those files. But 40 bits is about five characters, which is just over a word, so in theory the 40 bit models have the same information that the bag of words model (at 79% accuracy) has.
As we can see, characters do well, even at the same bit sizes. Basically you get a ton of binary sequence features from raw bits that are just confusing the classifier. Zipped bits do markedly worse than raw bits. The reason the bit-based models don't extend further is because it started taking gigantic amounts of memory (more than my poor 32gb machine could handle) to process and train on those files. But 40 bits is about five characters, which is just over a word, so in theory the 40 bit models have the same information that the bag of words model (at 79% accuracy) has.So yes, it does seem that the input representation matters. This isn't shocking, but I've never seen anyone actually try something like this before.
01 June 2009
30 May 2009
Semi-supervised or Semi-unsupervised? (SSL-NLP invited papers)
Kevin Duh not-so-recently asked me to write a "position piece" for the workshop he's co-organizing on semi-supervised learning in NLP. I not-so-recently agreed. And recently I actually wrote said position piece. You can also find a link off the workshop page. I hope people recognize that it's intentionally a bit tongue-in-cheek. If you want to discuss this stuff or related things in general, come to the panel at NAACL from 4:25 to 5:25 on 4 June at the workshop! You can read the paper for more information, but my basic point is that we can typically divide semi-supervised approached into one lump (semi-supervised) that work reasonably well with only labeled data and are just improved with unlabeled data and one lump (semi-unsupervised) that work reasonably well with only unlabeled data and are just improved with labeled data. The former are typically encode lots of prior information; the latter do not. Let's combine! (Okay, my claim is more nuanced than that, but that's the high-order bit.)
29 May 2009
How to reduce reviewing overhead?
It's past most reviewing time (for the year), so somehow conversations I have with folks I visit tend to gravitate toward the awfulness of reviewing. That is, there is too much to review and too much garbage among it (of course, garbage can be slightly subjective). Reviewing plays a very important role but is a very fallible system, as everyone knows, both in terms of precision and recall. Sometimes there even seems to be evidence of abuse.
But this post isn't about good reviewing and bad reviewing. This is about whether it's possible to cut down on the sheer volume of reviewing. The key aspect of cutting down reviewing, to me, is that in order to be effective, the reduction has to be significant. I'll demonstrate by discussing a few ideas that have come up, and some notes about why I think they would or wouldn't work:
- Tiered reviewing (this was done at ICML this year). The model at ICML was that everyone was guaranteed two reviews, and only a third if your paper was "good enough." I applaud ICML for trying this, but as a reviewer I found it useless. First, it means that at most 1/3 of reviews are getting cut (assuming all papers are bad), but in practice it's probably more like 1/6 that get reduced. This means that if on average a reviewer would have gotten six papers to review, he will now get five. First, this is a very small decrease. Second, it comes with an additional swapping overhead: effectively I now have to review for ICML twice, which makes scheduling a much bigger pain. It's also harder for me to be self-consistent in my evaluations.
- Reject without review (this was suggested to me at dinner last night: if you'd like to de-anonymize yourself, feel free in comments). Give area chairs the power that editors of journals have to reject papers out of hand. This gives area chairs much more power (I actually think this is a good thing: area chairs are too often too lazy in my experience, but that's another post), so perhaps there would be a cap on the number of reject without reviews. If this number is less that about 20%, then my reviewing load will drop in expectation from 5 to 4, which, again, is not a big deal for me.
- Cap on submissions (again, a suggestion from dinner last night): authors may only submit one paper to any conference on which their name comes first. (Yes, I know, this doesn't work in theory land where authorship is alphabetical, but I'm trying to address our issues, not someone else's.) I've only twice in my life had two papers at a conference where my name came first, and maybe there was a third where I submitted two and one was rejected (I really can't remember). At NAACL this year, there are four such papers; at ACL there are two. If you assume these are equally distributed (which is probably a bad assumption, since the people who submit multiple first author papers at a conference probably submit stronger papers), then this is about 16 submissions to NAACL and 8 submissions to ACL. Again, which is maybe 1-4% of submitted papers: again, something that won't really affect me as a reviewer (this, even less than the above two).
- Strong encouragement of short papers (my idea, finally, but with tweaks from others): right now I think short papers are underutilized, perhaps partially because they're seen (rightly or wrongly) as less significant than "full" papers. I don't think this need be the case. Short papers definitely take less time to review. A great "short paper tweak" that was suggested to me is to allow only 3 pages of text, but essentially arbitrarily many pages of tables/figures (probably not arbitrarily, but at least a few... plus, maybe just make data online). This would encourage experimental evaluation papers to be submitted as shorts (currently these papers typically just get rejected as being longs because they don't introduce really new ideas, and rejected as shorts because its hard to fit lots of experiments in four pages). Many long papers that appear in ACL could easily be short papers (I would guesstimate somewhere around 50%), especially ones that have the flavor of "I took method X and problem Y and solved Y with X (where both are known)" or "I took known system X, did new tweak Y and got better results." One way to start encouraging short papers is to just have an option that reviews can say something like "I will accept this paper as a short paper but not a long paper -- please rewrite" and then just have it accepted (with some area chair supervision) without another round of reviewing. The understanding would have to be that it would be poor form as an author to pull your paper out just because it got accepted short rather than accepted long, and so authors might be encouraged just to submit short versions. (This is something that would take a few years to have an effect, since it would be partially social.)
- Multiple reviewer types (an idea that's been in the ether for a while). The idea would be that you have three reviewers for each paper, but each serves a specific role. For instance, one would exclusively check technical details. The other two could then ignore these. Or maybe one would be tasked with "does this problem/solution make sense." This would enable area chairs (yes, again, more work for area chairs) to assign reviewers to do things that they're good at. You'd still have to review as many papers, but you wouldn't have to do the same detailed level of review for all of them.
- Require non-student authors on papers to review 3 times as many papers as they submit to any given conference, no exceptions ("three" because that's how many reviews they will get for any given paper). I know several faculty to follow the model of "if there is a deadline, we will submit." I don't know how widespread this is. The idea is that even half-baked ideas will get garner reviews that can help direct the research. I try to avoid offending people here, but that's what colleagues are for: please stop wasting my time as a reviewer by submitting papers like this. If they get rejected, you've wasted my time; if they get accepted, it's embarrassing for you (unless you take time by camera ready to make them good, which happens only some of the time). Equating "last author" = "senior person", there were two people at NAACL who have three papers and nine who have two. This means that these two people (who in expectation submitted 12 papers -- probably not true, probably more like 4 or 5) should have reviewed 12-15 papers. The nine should probably have reviewed 9-12 papers. I doubt they did. (I hope these two people know that I'm not trying to say they're evil in any way :P.) At ACL, there are four people with three papers (one is a dupe with a three from NAACL -- you know who you are!) and eight people with two. This would have the added benefit of having lots of reviews done by senior people (i.e., no crummy grad student reviews) with the potential downside that these people would gain more control over the community (which could be good or bad -- it's not a priori obvious that being able to do work that leads to many publications is highly correlated with being able to identify good work done by others).
- Make the job of the reviewer more clear. Right now, most reviews I read have a schizophrenic feel. On the one hand, the reviewer justifies his rating to the area chair. On the other, he provides (what he sees as) useful feedback to the authors. I know that in my own reviewing, I have cut down on the latter. This is largely in reaction to the "submit anything and everything" model that some people have. I'll typically give (what I hope is) useful feedback to papers I rate highly, largely because I have questions whose answers I am curious about, but for lower ranked papers (1-3), I tend to say things like "You claim X but your experiments only demonstrate Y." Rather than "[that] + ... and in order to show Y you should do Z." Perhaps I would revert to my old ways if I had less to review, but this was a choice I made about a year ago.
I actually think that together, some of these ideas could have a significant impact. For instance, I would imagine 2 and 4 together would probably cut a 5-6 paper review down to a 3-4 paper review, and doing 6 on top of this would probably take the average person's review load down maybe one more. Overall, perhaps a 50% reduction in number of papers to review, unless you're one of the types who submits lots of papers. I'd personally like to see it done!
