In a previous post's comments, we talked about Bayes rule and things like that. This got me wondering about the following question:
If we know p(A) and p(B|A), we can reconstruct p(A|B) perfectly by Bayes' rule. What if we only have estimates of p(A) and p(B|A)? How does the quality of the reconstruction of p(A|B) vary as a function of the quality of the estimates of the marginal and conditional?I feel like there have to be results along these lines, but I was unable to find them. My next attempt was to prove something, which failed miserably after a few hours. So, as a good empiricist and lazy(/bad) theorist, I designed a simple experiment.
Let A and B be binary variables. Let's generate a random joint distribution p(A,B), which has four cells for the four possible combinations of values of A and B. From this, we can directly compute the true marginal p(A) and the true conditionals p(B|A) and p(A|B).
Now, let's pick some "estimate" q(A) and q(B|A). You can think of these as a "noisy" version of p(A) and p(B|A). Given q(A) and q(B|A), we can compute an estimate a reconstructed joint distribution q(A,B) = q(A)q(B|A), as well as a reconstructed conditional distribution q(A|B) = q(A)q(B|A) / Z(q), where Z(q) is computed according to q. We can then compare q(A,B) to the true p(A,B) and q(A|B) to the true p(A|B) and measure how far they are.
At this point we have to decide what our measurement (divergence) function is. I tried three: variational distance (max absolute difference), l1 distance (sum absolute difference) and KL divergence. To be absolutely pedantic, I will define the versions of these that I used. First, the KL variants:
KL( p(A) || q(A) ) = sum_a p(a) log [ p(a) / q(a) ]Note that the direction is q from p (chosen because p is the "true" distribution) and that this also has the advantage that the conditional KL is based on p(B), which (in this case) is known exactly and is "correct."
KL( p(A,B) || q(A,B) ) = sum_{a,b} p(a,b) log [ p(a,b) / q(a,b) ]
KL( p(A|B) || q(A|B) ) = sum_b p(b) KL( p(A|B=b) || q(A|B=b) )
By analogy, for l1 distance we have:
l1(p(A), q(A)) = sum_a |p(a) - q(a)|Note that this last one might be slightly non-standard, but is parallel to the KL definition.
l1(p(A,B), q(A,B)) = sum_{a,b} |p(a) - q(a)|
l1(p(A|B),q(A|B)) = sum_b p(b) l1(p(A|B=b), q(A|B=b))
Similarly, for variational distance:
var(p(A), q(A)) = max_a |p(a) - q(a)|Okay, so now for the experiment. First I generate a random (uniform) true joint distribution p(A,B). I then run through 1,000,000 possible q(A,B), where each of the three sufficient statistics are chosen from [0.01, 0.02, ... 0.99]. I then conditionalize and marginalize these in all the relevant ways and compute KL. Finally, I generate plots like the following very representative example for KL:
var(p(A,B), q(A,B)) = max_{a,b} |p(a) - q(a)|
var(p(A|B),q(A|B)) = sum_b p(b) var(p(A|B=b), q(A|B=b))
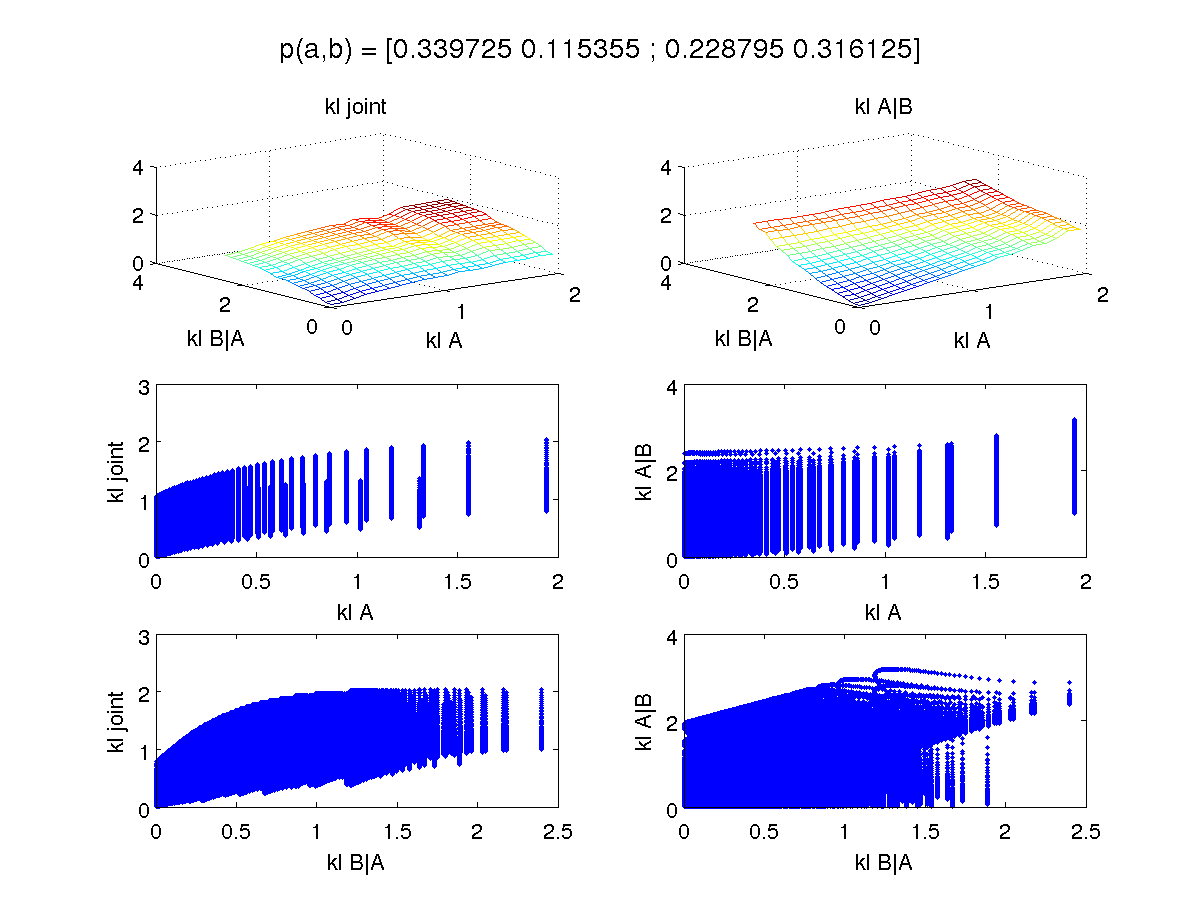
This example is fairly benign: as the approximations become worse, so do both of the recovered distributions, in a fairly linear way until a plateau. From the bottom row, you can see that it's more important to get the conditional right than the marginal (you can have a marginal that's quite far--eg., a KL of 1.5--and still get an almost perfect recovery of the conditional or joint, but this is not true for large differences in the conditional B|A.
One strange thing is that you often (for different true joints) see results that look like:

One can ask if this is an artifact of KL. So let's switch to L1 and variational for the first set of plots:
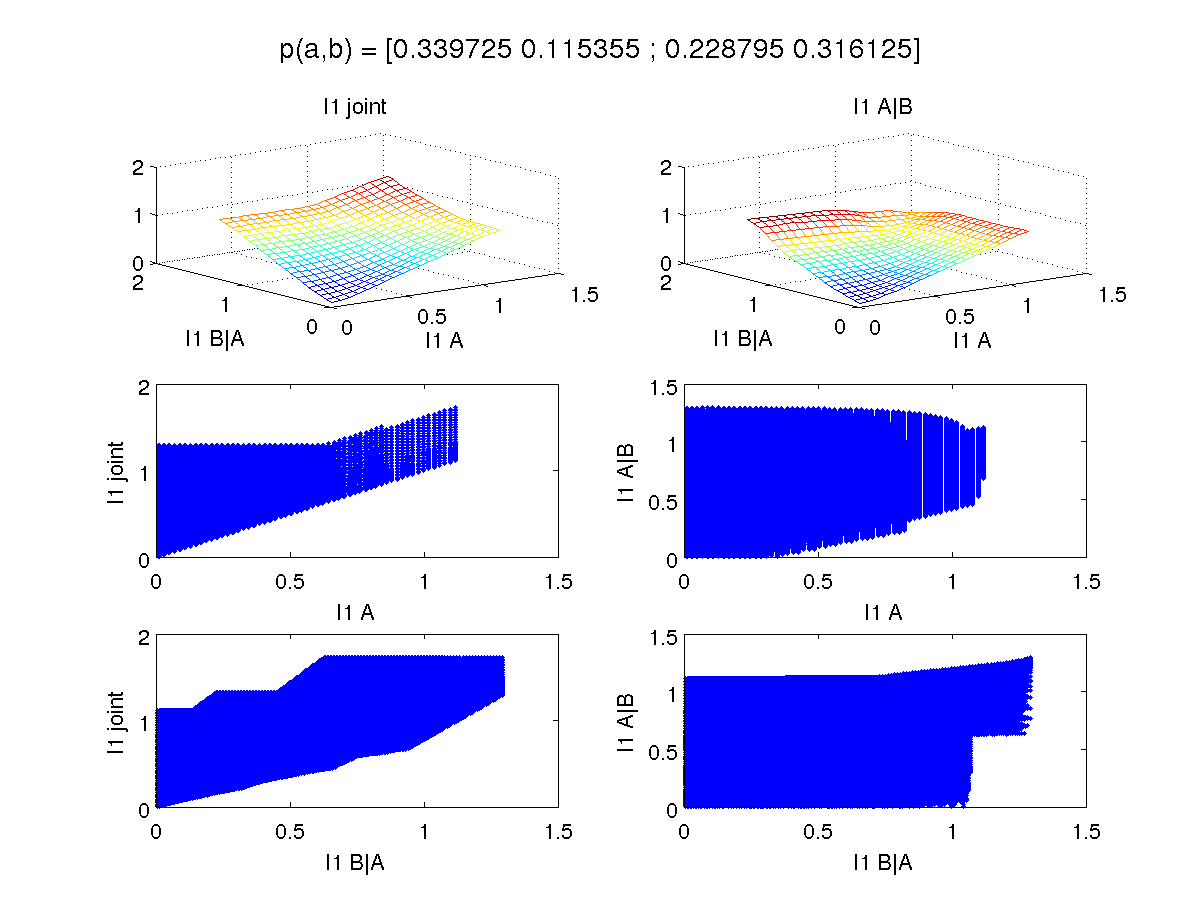
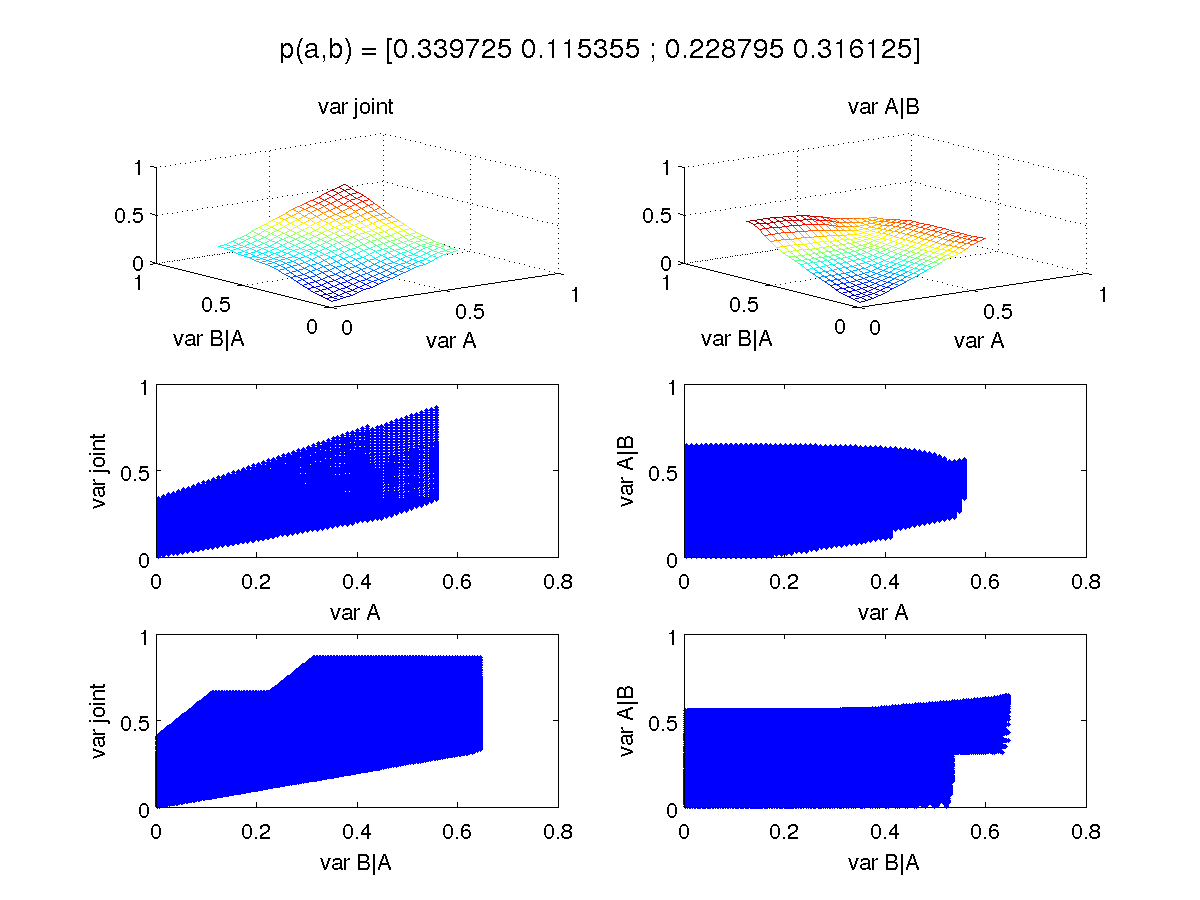
For the example that gave rise to the weird KL results, we have the following for L1:
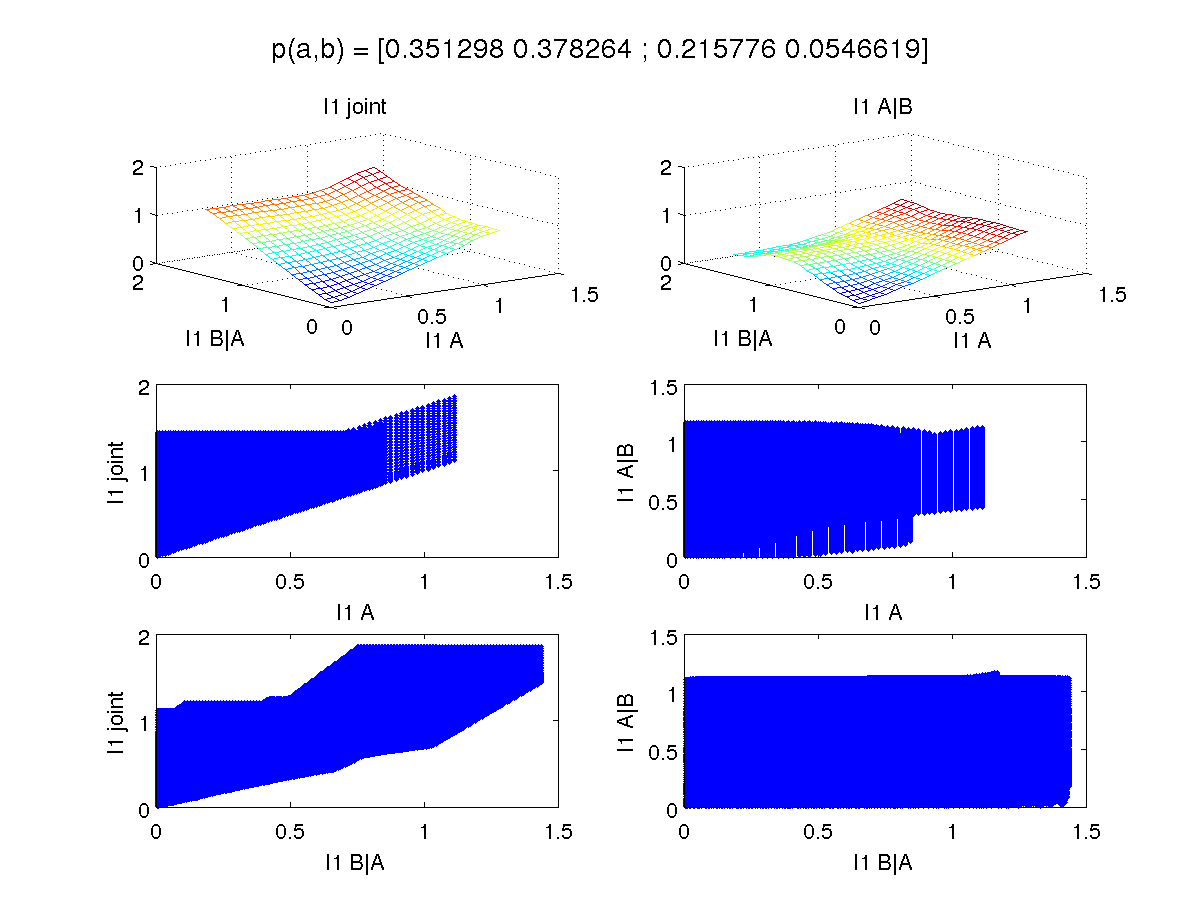

Okay, so it's totally entirely possible (perhaps probable?) that there's a bug in my code. If you'd like to look, check out mykl.m and myklrun.m (yes, it's matlab). Let me know in the comments if there are bugs. If you'd like to look at more examples, check out all ten examples.

1 comment:
This becomes an interesting question if there's a way to refine your estimates of p(A) and p(B|A) by further sampling (say). Because then I'd imagine the right thing to do would be to do some kind of adaptive sampling to make sure that "dimensions' not covered all by one coordinate are compensated by extra sampling in the other coordinate when doing the inner product etc.
No answer, but this makes me think :)
Post a Comment